![[Thanh tra ma giáo] Dgraph](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1765139308939%2F4f5364bc-327d-4941-8109-b0918e3aab4b.webp&w=3840&q=75)
Chào mừng các bạn đến với series “Thanh tra ma giáo” – chuỗi bài viết chuyên điều tra và đánh giá các công nghệ trên thị trường. Mở đầu series, tôi xin giới thiệu ứng viên đầu tiên: Dgraph – một Graph Database nằm trong top 10 bảng xếp hạng DB-Engine (tính tới thời điểm hiện tại của bài viết).
Bài viết này dựa hoàn toàn trên Whitepaper và tài liệu kỹ thuật chính thức của Dgraph, không “hóng hớt” từ các nguồn tin không chính thống. Chi tiết Whitepaper anh em có thể xem tại đây (hoặc link dự phòng).
1. Điểm khác biệt cốt lõi: Sharding theo Relationship#
Dgraph solves the join depth problem with a unique sharding mechanism. Instead of sharding by entities, as most systems do, Dgraph shards by relationships. Dgraph’s unique way of sharding data is inspired by research at Google, which shows that the overall latency of a query is greater than the latency of the slowest component. The more servers a query touches to execute, the slower the query latency would be. [1] By doing relationship based sharding, Dgraph can execute a join or traversal in a single network call (with a backup network call to replica if the first is slow), irrespective of the size of the cluster or the input set of entities. [2] Dgraph executes arbitrary-depth joins without network broadcasts or collecting data in a central place.
…
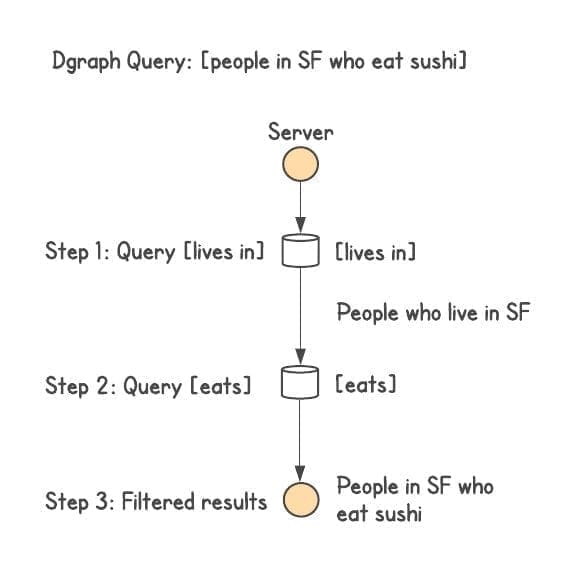
For a query which asks for [people who live in SF and eat Sushi], Dgraph would execute one network call to server containing lives in and do a single lookup for all the people who live in SF. In the second step, it would take those results and send them over to server containing eats, do a single lookup to get all the people who eat Sushi, and intersect with the previous step’s result set to generate the final list of people from SF who eat Sushi. In a similar fashion, this result set can then be further filtered/joined, each join executing in one network call.
Tôi sẽ giải thích một chút cho đoạn trên: Dữ liệu trong Graph thông thường sẽ được biểu diễn dưới dạng triplet Subject -> Predicate -> Object, hay còn gọi là [S P O] .
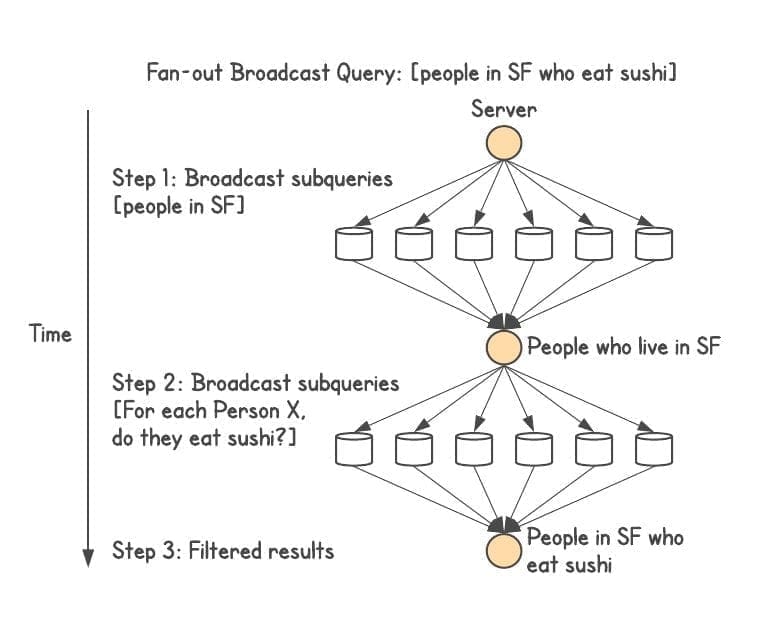
Hầu hết Graph Database truyền thống shard (phân mảnh) dữ liệu theo entity (Subject hoặc Object). Điều này dẫn đến một vấn đề: khi truy vấn kiểu [? P O] (tìm tất cả Subject có quan hệ Predicate với một Object cụ thể), hệ thống phải broadcast (fanout) yêu cầu đến tất cả các node, rồi tập hợp kết quả. Thời gian phản hồi (P99) phụ thuộc vào node chậm nhất.
Dgraph tuyên bố giải quyết vấn đề này bằng cách sharding theo relationship (predicate). Mỗi predicate (ví dụ: live in, eat) được gán cho một shard cụ thể. Cách tiếp cận này được lấy cảm hứng từ nghiên cứu của Google: độ trễ tổng thể của truy vấn thường bị chi phối bởi node chậm nhất.
Ưu điểm:
Theo trích dẫn [1], Dgraph tuyên bố:
"By doing relationship based sharding, Dgraph can execute a join or traversal in a single network call...". Từcanở đây rất quan trọng – nó chỉ xảy ra trong trường hợp tốt nhất (best-case) khi dữ liệu cần join nằm chung shard, chứ không đảm bảo cho mọi truy vấn.Truy vấn theo predicate lý thuyết là nhanh hơn. Ví dụ: "Liệt kê danh sách người đang sống tại Hà Nội" vì chỉ cần giao tiếp với duy nhất shard chứa predicate
sống_tại.
Nhược điểm:
- Truy vấn thông tin đầy đủ của một Entity thì chậm. Vì các predicate của một entity bị phân tán trên nhiều shard, để lấy toàn bộ thông tin của entity, hệ thống phải query fanout đến nhiều node. Ví dụ như câu truy vấn sau:
Liệt kê toàn bộ các thông tin hiện đang có của user_123
+ Node 0: [user_123 - sống tại - Hà Nội], [user_123 - quê - Hải Dương]
+ Node 1: [user_123 - giới tính - nam]
+ Node 2: [user_123 - độ tuổi - 25_35]
+ …
- Join nhiều predicate có thể thành nối tiếp: Theo trích dẫn [2]:
"each join executing in one network call". Điều này có nghĩa, với truy vấn phức tạp như "Tìm người là nữ, quê Hải Dương và sống tại Hà Nội", Dgraph có thể xử lý tuần tự: gọi shardgiới_tínhlọc ra người nữ → gửi kết quả đó đến shardquêđể lọc tiếp → rồi mới gửi đến shardsống_tại. Cách này tránh tập trung dữ liệu về một chỗ nhưng có thể tăng độ trễ tổng thể so với xử lý song song.
Liệt kê danh sách các user là nữ, quê ở Hải Dương và đang sống tại Hà Nội.
Cách Dgraph đang sử dụng:
→ Node 1: […? - giới tính - nữ] = danh sách các user là nữ
→ Node 0:
→ […? - quê - Hải Dương] = danh sách các user là nữ, quê ở Hải Dương
→ […? - sống tại - Hà Nội] = danh sách các user là nữ, quê ở Hải Dương và đang sống tại Hà Nội
2. Consistency, Availability và Vấn đề Resharding#
Dgraph automatically shards data into machines, as the amount of data or the number of servers change, and automatically reshards data to move it across servers to balance the load.
…
While this process sounds pretty straighforward, there are many race and edge conditions here which can cause transactional correctness to be violated as shown by Jepsen tests.
…
Future work here is to allow writes during the shard move, which depending upon the size of the shard can take some time.
Dgraph có cơ chế tự động reshard khi dữ liệu hoặc số lượng server thay đổi.
Ưu điểm:
- Automatically reshard giúp giảm tải công việc vận hành.
Nhược điểm:
Dgraph nghiêng về CP (trong CAP): Trong quá trình di chuyển shard, Dgraph đánh dấu shard đó là read-only. Nó chấp nhận đánh đổi Availability (tính sẵn sàng cao) để đảm bảo Consistency (tính nhất quán) trong giai đoạn này.
Reshard có thể làm trầm trọng thêm tình trạng quá tải: Nếu một node đang bị tải cao, việc tự động reshard và di chuyển dữ liệu từ node đó có thể khiến tình hình tồi tệ hơn do tốn thêm tài nguyên mạng và CPU.
Vấn đề nghiêm trọng về ACID (theo đánh giá của Jepsen): Tổ chức Jepsen nổi tiếng về kiểm thử tính nhất quán distributed systems đã chỉ ra nhiều lỗi trong Dgraph:
Hàng loạt vi phạm ACID và cả deadlock xảy ra trong quá trình rebalance shard.
Dữ liệu có thể bị mất mát hoặc trùng lặp.
Dgraph sử dụng Snapshot Isolation (không phải mức Serializable cao nhất), vẫn có nguy cơ gặp các vấn đề như Write Skew, Lost Update,… (tham khảo bài Transaction Isolation 101: Concurrency Control Problem và Transaction Isolation 102: Isolation Level để hiểu rõ hơn)
3. Storage Engine – Badger: Lợi thế hay Gánh nặng?#
Dgraph data is stored in an embeddable key-value database called Badger for data input-output on disk. Badger is an LSM-tree based design, but differs from others in how it can optionally store values separately from keys to generate a much smaller LSM tree, which results in both lower write and read amplification. Various benchmarks run by the team show Badger to provide equivalent or faster writes than other LSM based DBs, while providing equivalent read latencies compared to B+-tree based DBs (which tend to provide much faster reads than LSM trees).
Dựa theo tài liệu về Badger được giới thiệu tại đây, tôi sẽ tóm tắt qua một số điểm chính như sau:
RocksDB được viết bằng C++
Badger được viết lại bằng Golang, với mục đích để Dgraph (Golang) có thể tương tác trực tiếp bằng Native Go, không cần thông qua Cgo.
Cơ chế hoạt động:
Thay vì lưu cả <Key, Value> vào LSM-tree, Badger chỉ lưu <Key, Pointer> (pointer trỏ đến vị trí của Value trong file Write-Ahead Log - WAL riêng biệt). Value được lưu trong file value log (vlog).
Ví dụ lưu trữ triplet:
<0x01> <follower> <0xab> .
<0x01> <follower> <0xbc> .
<0x01> <follower> <0xcd> .
...
Sẽ được nhóm lại và lưu vào LSM-tree dưới dạng:
Key =
<follower, 0x01>Value =
<0xab, 0xbc, 0xcd, ...>
Truy vấn
[S P ?]tương ứng vớiGet(Key=<P,S>)Truy vấn
[? P O]tương ứng vớiIterate(KeyPrefix=P)
Ưu điểm:
Giảm Write/Read Amplification: Kích thước LSM-tree (chứa key + pointer) nhỏ đi rất nhiều so với chứa cả value, dẫn đến ít phải compaction hơn, giảm kích thước đĩa và tăng tốc độ đọc/ghi.
Performance trên SSD: Benchmark của team Badger (chạy trên NVMe SSD) cho thấy nó có hiệu suất ngang ngửa hoặc vượt trội so với RocksDB (LSM-tree) và các DB dùng B+-tree cho một số tác vụ.
Nhược điểm:
Tốc độ Iterate chậm: Do phải thực hiện nhiều random read từ file value log (VLog) để lấy value. Điều này gây Disk I/O cao trên ổ HDD thông thường. Nhược điểm này được giảm nhẹ khi sử dụng SSD.
Phức tạp hóa: Việc tự phát triển Badger thay vì dùng engine đã được kiểm chứng như RocksDB (dù để tránh dùng Cgo trong Go) đồng nghĩa với việc tự “reinvent the wheel” và gánh thêm gánh nặng phát triển, bảo trì, sửa lỗi.
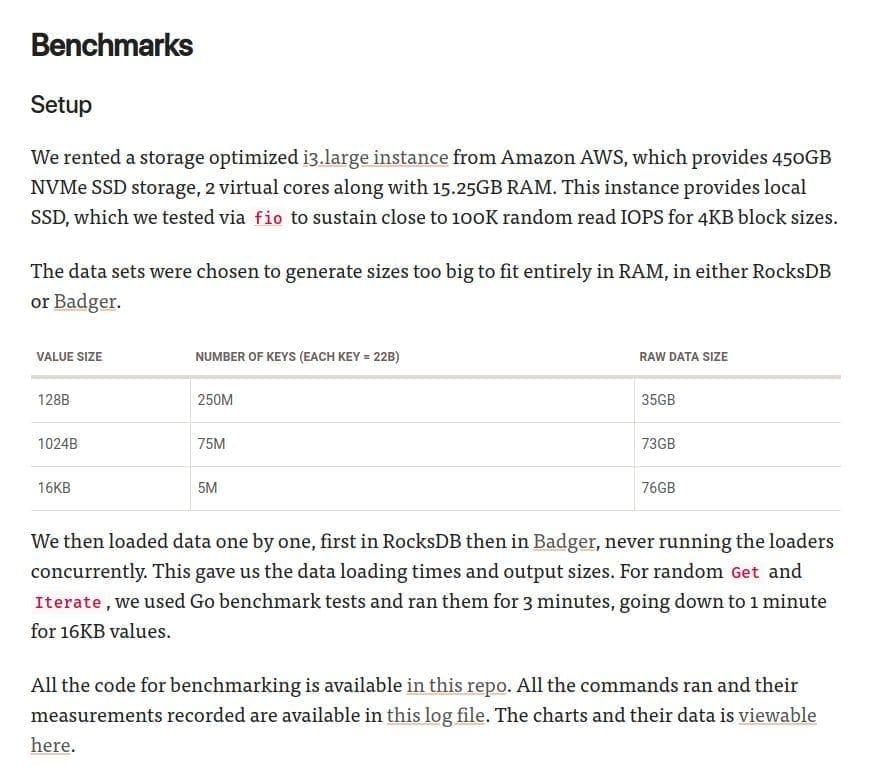
Thực tế, benchmark mà tác giả Badger thực hiện đều đang sử dụng SSD. Nhờ Read Amplication thấp và loại bỏ đi các thứ như transaction, versioning, snapshot nên cũng dễ hiểu vì sao Badger lại nhanh hơn RocksDB trên môi trường SSD.
4. Cache: Gần như Không tồn tại#
We had removed data caching from Dgraph due to heavy read-write contention, and built a new, contention-free Go cache library to aid our reads. Work is underway in integrating that with Dgraph. Dgraph does not have any query or response caching — such a cache would be difficult to maintain in an MVCC environment where each read can have different results, based on its timestamp.
Nhược điểm:
- Dgraph hiện đang không có cache
Điều này là một điểm trừ lớn cho workload cần đọc lặp lại. Lý do được đưa ra là trong môi trường MVCC (Multi-Version Concurrency Control), mỗi lần đọc ở một timestamp khác nhau có thể cho kết quả khác, khiến cache trở nên khó duy trì. Tuy nhiên, họ cũng đề cập đang xây dựng một thư viện cache mới cho Go để tích hợp trong tương lai.
5. Đánh giá tổng quan#
Dù mới chỉ xem xét những yếu tố thiết yếu của 1 Database, chưa đi sâu vào các chi tiết như MVCC hay Lock-free Transaction,… Dgraph đã bộc lộ quá nhiều điểm đáng lo ngại (theo như tác giả nói thì hiện vẫn chưa có phương án khắc phục).
Việc Dgraph có quá nhiều lỗi như này, theo tôi nhận định là do có vẻ như nhà phát triển Dgraph đã quá tham vọng khi cùng lúc tối ưu hiệu suất cao (lock-free, sharding đặc biệt, tự viết storage engine), lại cố gắng triển khai distributed transaction phức tạp.
Ngoài ra, họ cũng tự “reinvent the wheel" cho nhiều thành phần hệ thống, thay vì sử dụng các công nghệ đã được kiểm chứng như ZooKeeper, RocksDB,… Ở thời điểm được phân tích, nó dường như chưa đủ chín chắn và ổn định để sử dụng trong các hệ thống production đòi hỏi tính nhất quán và độ tin cậy cao. Các tuyên bố về performance và ACID cần được nhìn nhận một cách thận trọng. Tôi xin phép dừng đi sâu hơn tại đây và đưa ra kết luận luôn:
Xếp loại: Ma giáo
Điểm: 4/10