Tag: Data Structure
-
![[Thanh tra ma giáo] Dgraph](https://dogy.io/wp-content/uploads/2021/04/bbPFlogos_1000px_dgraph-800x800-1.png)
[Thanh tra ma giáo] Dgraph
Chào mừng các bạn đến với series “Thanh tra ma giáo” – chuỗi bài viết chuyên về điều tra và đánh giá các công nghệ trên thị trường hiện nay: liệu chúng có thật sự được như lời quảng cáo hay không? Hay đó chỉ là các chiêu trò ma giáo, bánh vẽ marketing nhằm…
-

Database 303: Column-Oriented Storage
Nhắc lại ở các phần trước, ta đã được làm quen với những Hash Index, LSM-Trees Index hay B-Trees Index. Tuy nhiên, mình phải thú thực với các bạn rằng: tất cả các loại index đó đều chỉ phù hợp cho các hệ thống OLTP. Điểm khác biệt giữa OLTP và OLAP thì mình đã…
-

Database 201: B-Tree
B-Tree là 1 kiến trúc index được mô phỏng dựa trên cấu trúc dữ liệu B-Tree, nhờ đó nó cũng được thừa kế tính năng lưu trữ cặp key-value dưới dạng có thứ tự. Điều này giúp cho nó có thể đáp ứng các loại truy vấn tìm kiếm key cũng như range query. Tuy…
-

Database 103: SSTable và LSM-Tree
SSTable là gì? Trước khi tiếp tục cái series về Database, ta sẽ tìm hiểu qua trước về Sorted String Table, hay còn được gọi là SSTable. Về bản chất thì nó khá giống với kiến trúc Log file được đề cập từ 2 phần trước: Điểm khác biệt duy nhất đó là: mỗi key…
-
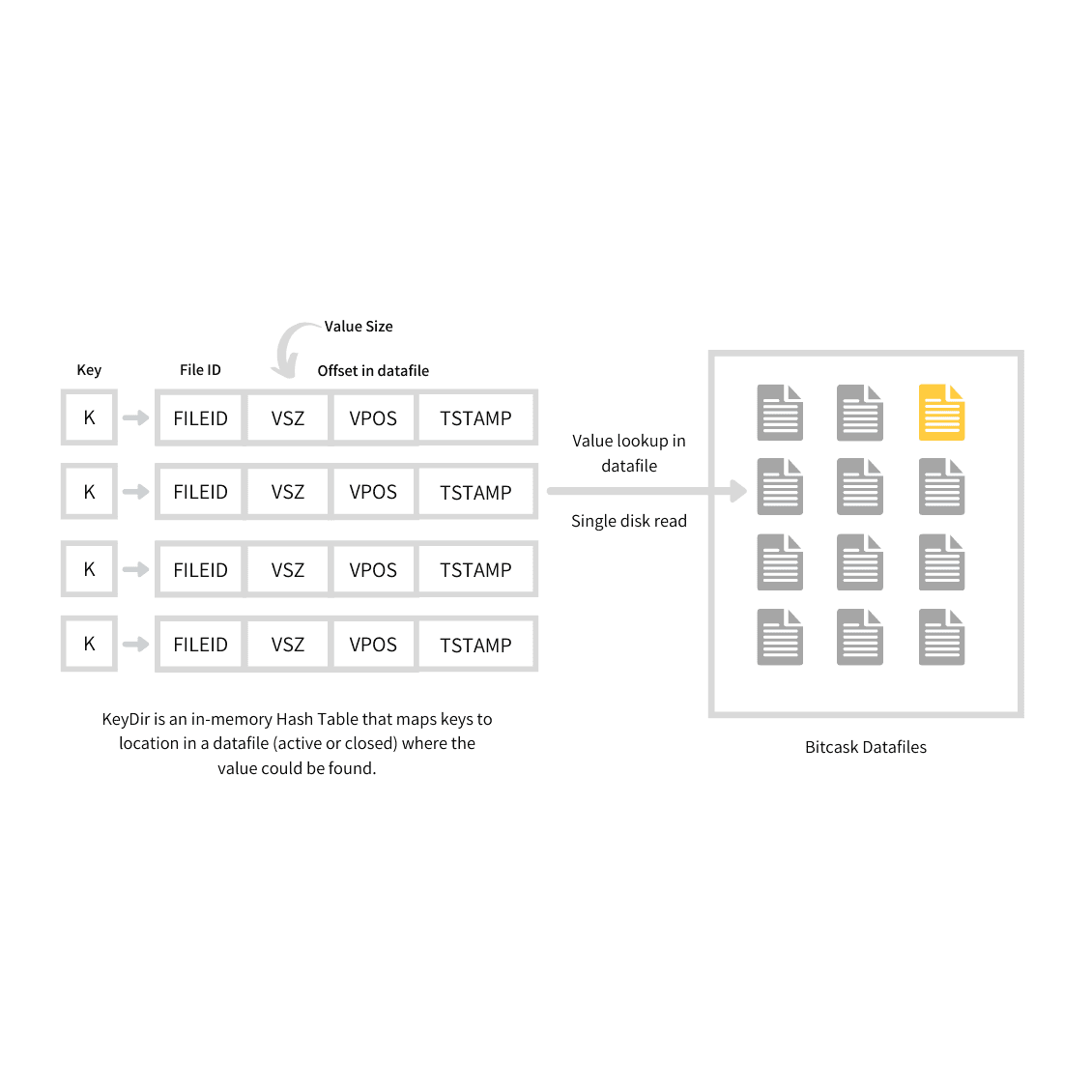
Database 102: Hash Index
Ta sẽ tiếp tục cải tiến từ cấu trúc log file của bài trước (Database 101: Log Structured Storage). Ý tưởng lần này bắt nguồn từ sự tương đồng giữa Key-Value Store và cấu trúc dữ liệu HashMap (Hash Table) – thường đã có sẵn trong hầu hết các ngôn ngữ lập trình hiện nay.…
-
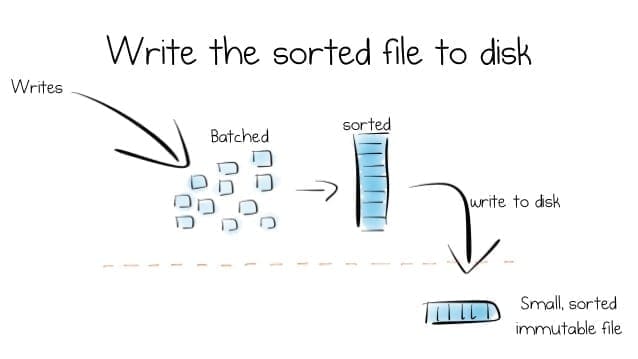
Database 101: Log Structured Storage
Log Structured Storage là trường phái Database dựa trên Append-only Log, tức là dữ liệu được ghi lưu lại dưới dạng log, chỉ có ghi xuống cuối file chứ không thể ghi đè. Chỉ mới được phổ biến gần đây, tuy nhiên xét về sự đơn giản (mà vẫn hiệu quả) thì nó xứng đáng…
-
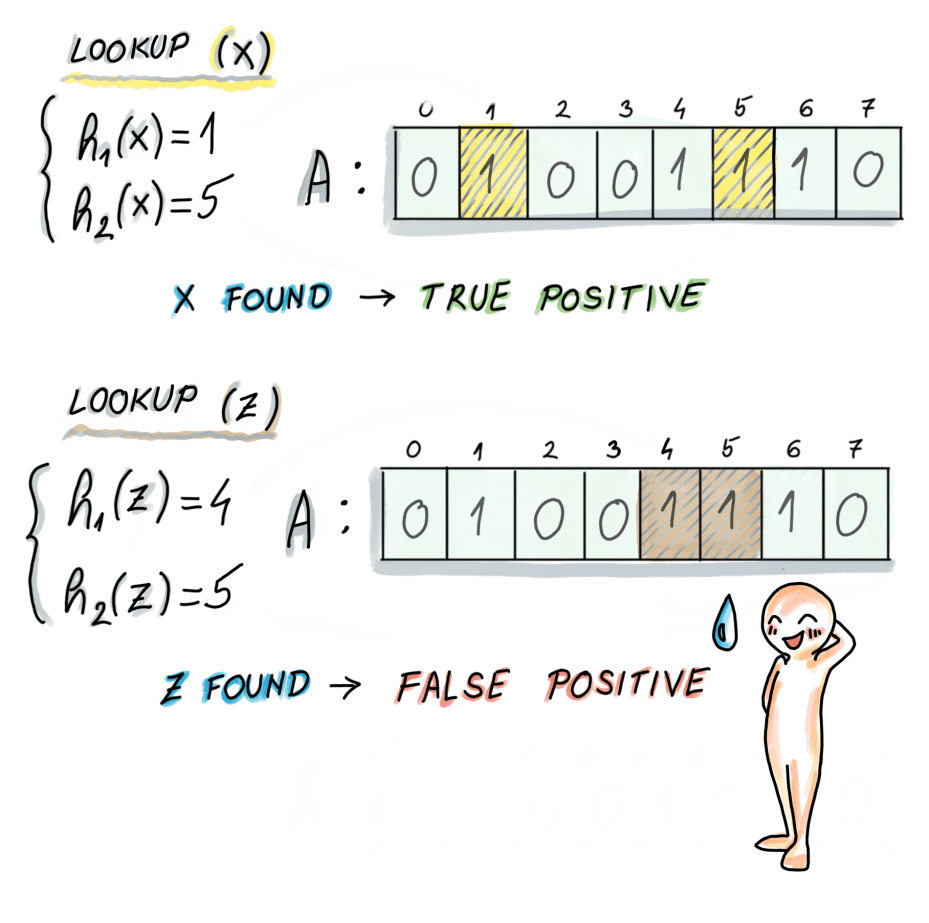
Bloom Filter
Bloom filter là 1 cấu trúc dữ liệu xác suất dùng để kiểm tra xem 1 phần tử có thuộc 1 tập dữ liệu hay không? Sở dĩ lý do lại là cấu trúc dữ liệu xác suất, bởi vì kết quả trả về của Bloom filter không đảm bảo chắc chắn rằng phần tử đó…