Category: Software Engineer
-

Halloween Problem – Lỗi Cập Nhật Vô Hạn Trong Cơ Sở Dữ Liệu
Năm 1976, trong quá trình thử nghiệm xây dựng bộ tối ưu hóa truy vấn (query optimizer) cho System R, các kỹ sư của IBM đã vô tình phát hiện ra một lỗi logic thú vị, mang tính học thuật cao. Vì được phát hiện đúng vào ngày lễ Halloween, vấn đề này đã chính…
-

Birthday Paradox
Gần đây, season 3 của Alice in Borderland đã được ra mắt trên Netflix. Trong muôn vàn content về bộ phim ở trên mạng, tôi vô tình bắt gặp hình ảnh này. Nó khiến tôi nhớ lại tháng ngày học môn An toàn thông tin ở Đại học, với những Bloom Filter hay Birthday Paradox.
-

Một số tip khi define schema
Trong thực tế, ta thường không tránh khỏi việc phải cập nhật schema (hay còn gọi là schema evolution). Giống như thiết kế kiến trúc hệ thống, việc define schema cũng cần phải được tính toán khéo léo để có thể dễ dàng tương thích cho cả phiên bản cũ và mới (Backward/Forward Compatibility). Bài…
-
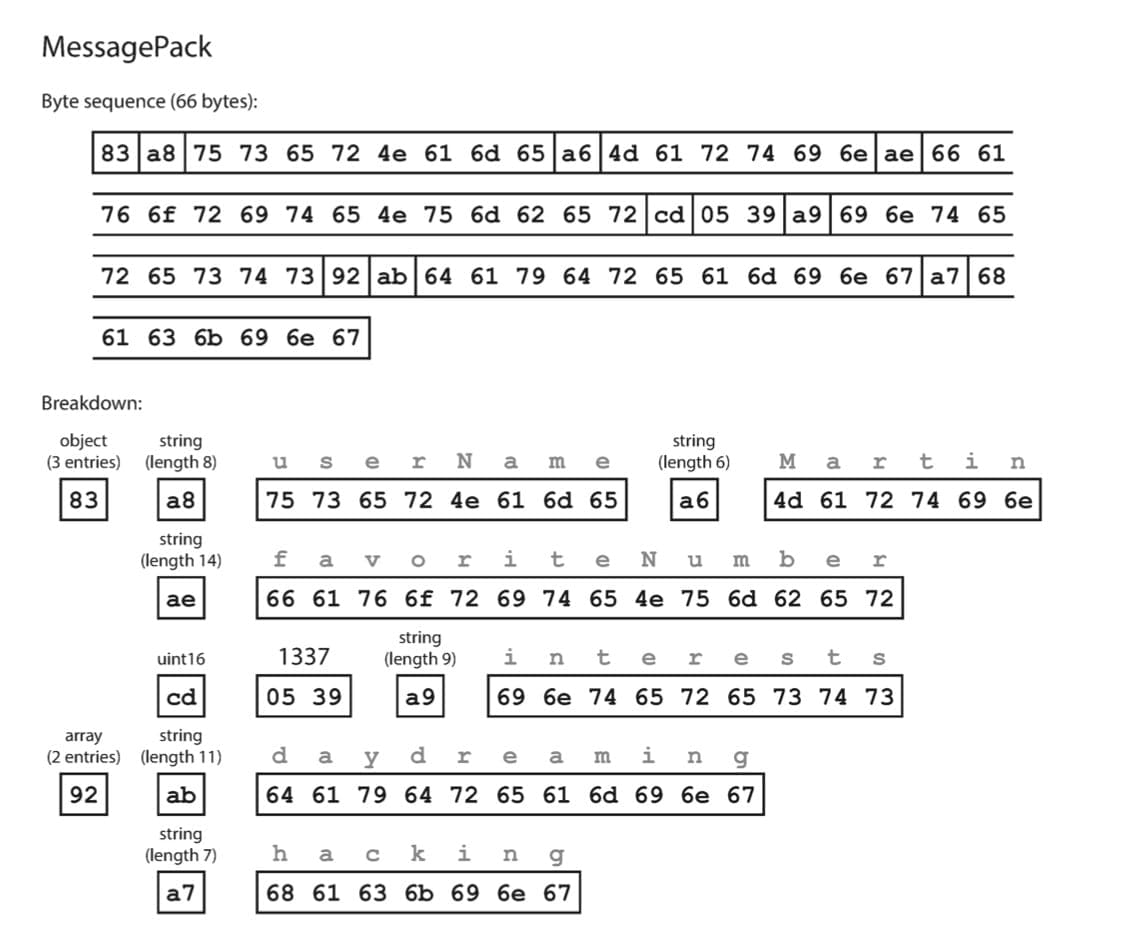
Protobuf, Thrift, Avro là gì?
Trong quá trình phát triển phần mềm, cách dữ liệu được lưu trữ xuống file hoặc được truyền sang service khác dưới định dạng gì là vô cùng quan trọng. Thông thường, đối với những dữ liệu trên file, ta có chọn kiểu định dạng “native” được hỗ trợ sẵn bởi ngôn ngữ lập trình,…
-
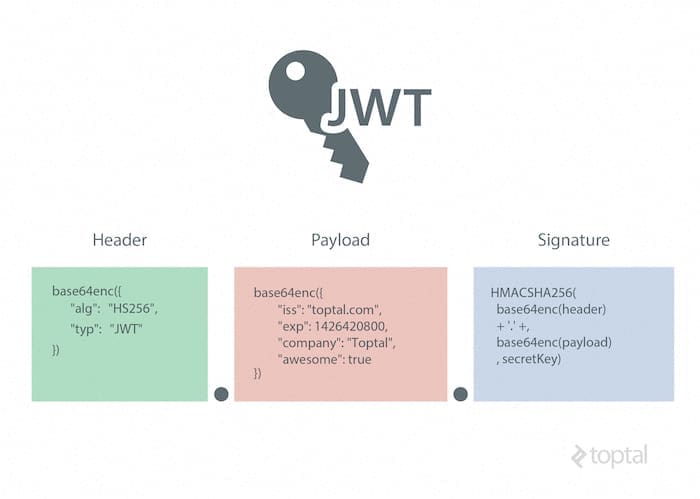
Khái niệm về JSON Web Token
Thời gian qua, mình có phải vật lộn với 1 framework mới, mày mò trong tài liệu hướng dẫn thì thấy nó có đề cập tới 1 phương pháp xác thực quyền truy cập (Authentication) bằng JSON Web Token (JWT). Sau khi đào sâu hơn về cái này, mình nhận thấy quả thực JWT nó còn tuyệt vời hơn ngoài mong đời và…
-
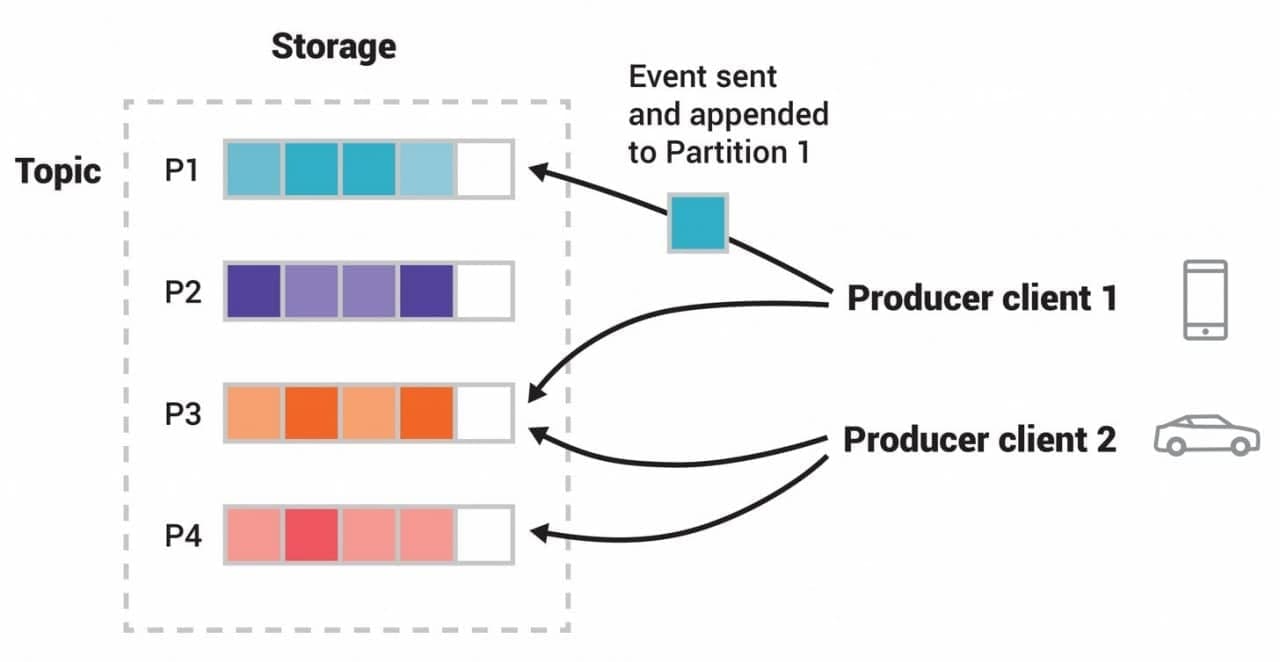
Tại sao Kafka lại nhanh tới vậy?
Kafka hỗ trợ một nền tảng thông lượng cao (throughput), phân tán (distributed), có khả năng chịu lỗi (fault-tolerant) với việc phân phối thông điệp có độ trễ thấp. Vậy Kafka được thiết kế như thế nào để đạt được độ trễ thấp như vậy? Hãy cùng tìm hiểu 3 cơ chế giúp Kafka đạt…
-
![[Thanh tra ma giáo] Dgraph](https://dogy.io/wp-content/uploads/2021/04/bbPFlogos_1000px_dgraph-800x800-1.png)
[Thanh tra ma giáo] Dgraph
Chào mừng các bạn đến với series “Thanh tra ma giáo” – chuỗi bài viết chuyên về điều tra và đánh giá các công nghệ trên thị trường hiện nay: liệu chúng có thật sự được như lời quảng cáo hay không? Hay đó chỉ là các chiêu trò ma giáo, bánh vẽ marketing nhằm…
-
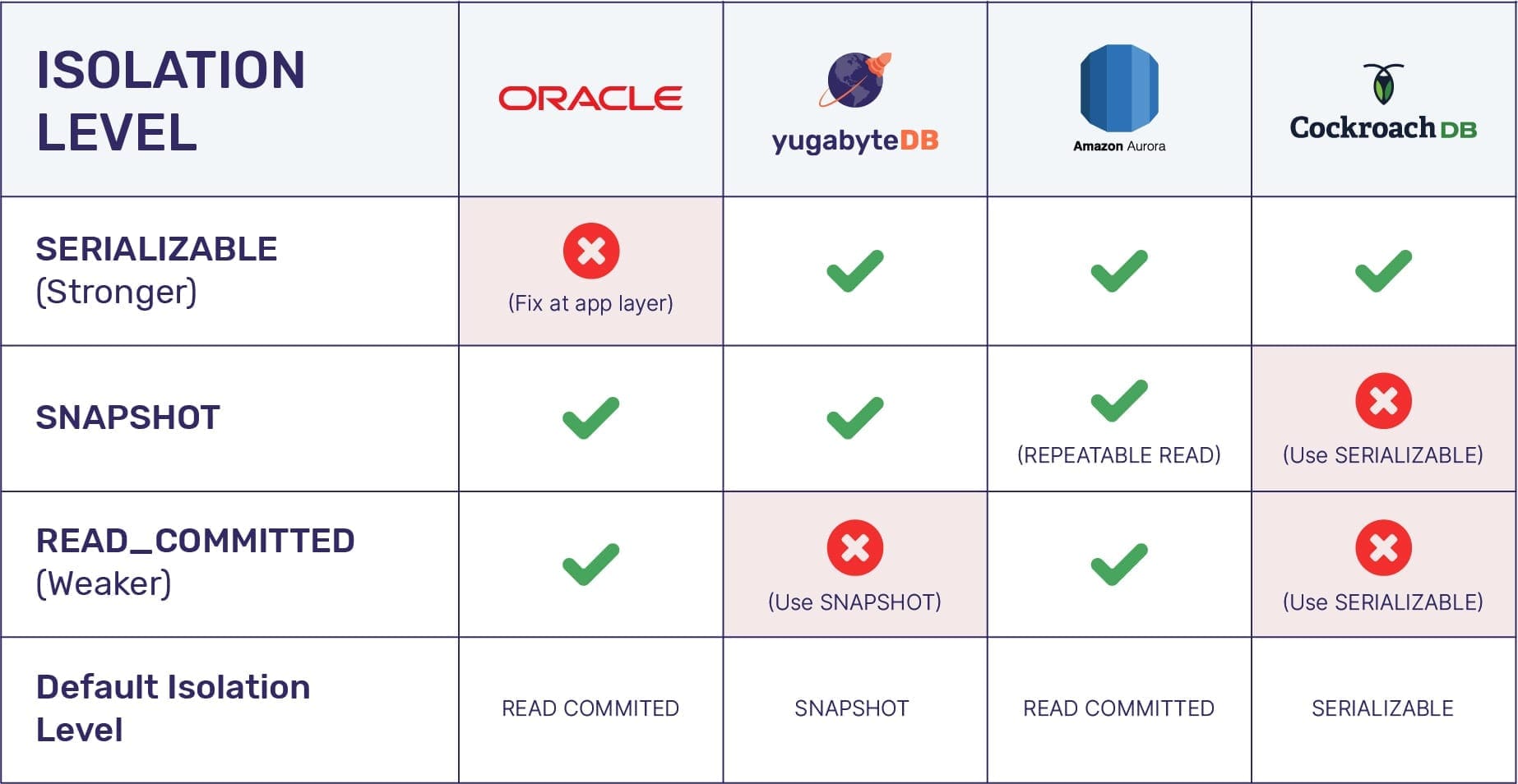
Transaction Isolation (Part 2): Isolation Level
Hiện nay, mỗi Database đều sử dụng phương pháp Isolation khác nhau. Thậm chí cũng có chuyện cùng một ý tưởng nhưng mỗi người lại triển khai khác nhau: cái thì chạy nhanh hơn, cái thì lại tốn ít bộ nhớ hơn, thậm chí cái còn có bug… Về cơ bản thì hiện nay có…
-
Transaction Isolation (Part 1): Concurrency Control Problem
Ở trong bài viết Bạn đã hiểu đúng về Transaction chưa?, tôi có giới thiệu qua về ACID. Trong số 4 từ khóa: A (Atomicity), C (Consistency), I (Isolation) và D (Durability), thì có lẽ Isolation là thành phần được mọi người quan tâm nhiều nhất, đặc biệt là những đối tượng sau nên đọc…
-

Bạn đã hiểu đúng về Transaction chưa?
Mình bắt gặp rất nhiều cuộc trò chuyện và hội thoại trong cuộc sống hàng ngày, nói về transaction trong Database, nhưng đa phần đều là quan niệm sai lầm: Qua bài này, mình sẽ giới thiệu lại tổng quan một chút về Transaction để mọi người hiểu rõ hơn về nó. Lợi ích ngay…
-

Database 303: Column-Oriented Storage
Nhắc lại ở các phần trước, ta đã được làm quen với những Hash Index, LSM-Trees Index hay B-Trees Index. Tuy nhiên, mình phải thú thực với các bạn rằng: tất cả các loại index đó đều chỉ phù hợp cho các hệ thống OLTP. Điểm khác biệt giữa OLTP và OLAP thì mình đã…
-
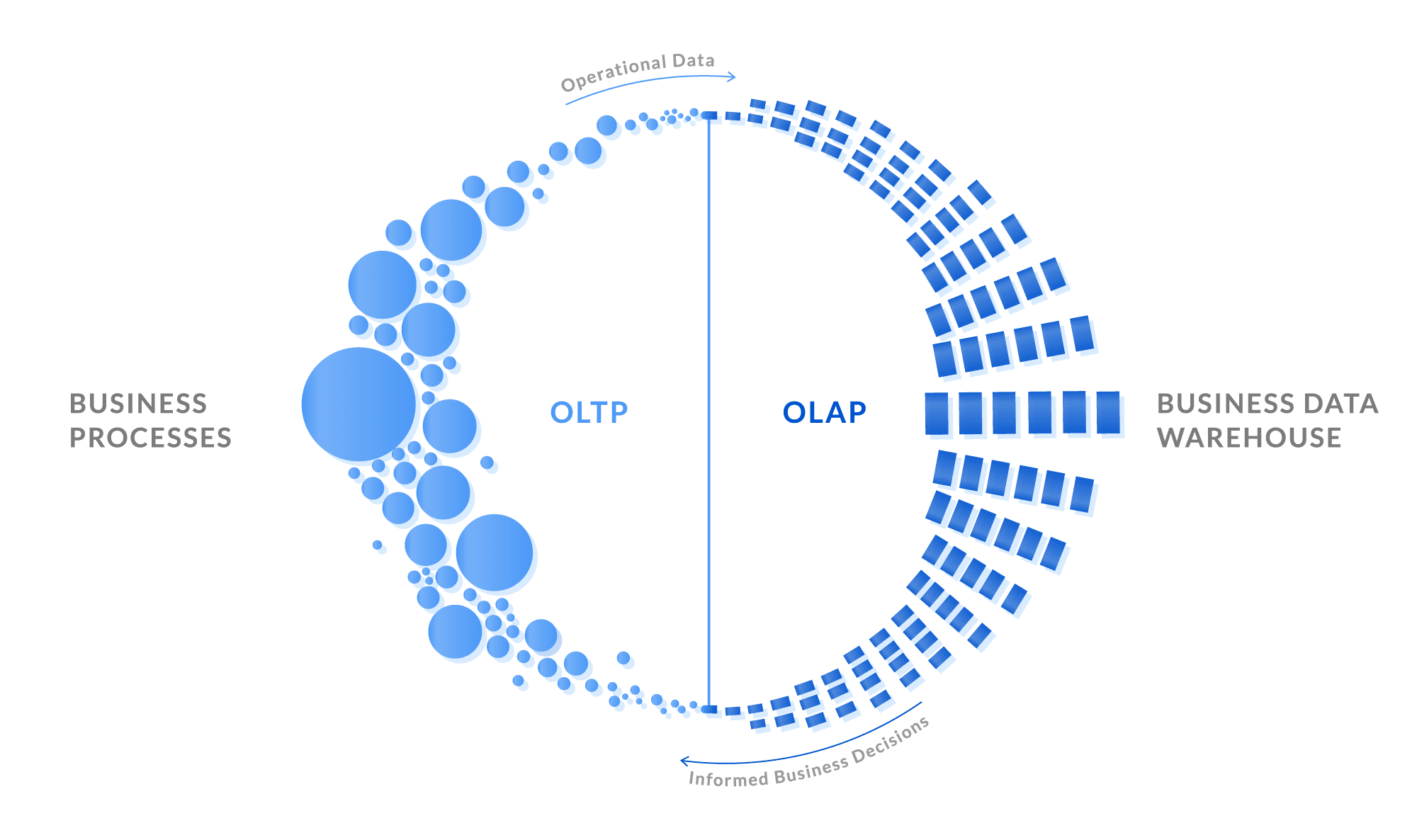
Database 302: OLTP hay OLAP?
Trong những thời kỳ ban đầu thuở sơ khai, cơ sở dữ liệu chủ yếu chỉ được sử dụng cho các hoạt động giao dịch thương mại: bán các mặt hàng, order nhà cung cấp, trả lương cho nhân viên,… Và khi mà nó bắt đầu được phổ biến rộng rãi hơn cho nhiều lĩnh…
-
Backward and Forward compatibility with Java Jackson ObjectMapper
Đối với các chương trình nằm ở phía server-side, chúng ta sẽ gặp phải vấn đề downtime khi cần triển khai upgrade code mới. Để giải quyết vấn đề này, ta thường nhân rộng service thành nhiều replica (>= 3) và sử dụng kỹ thuật rolling upgrade: từ từ triển khai upgrade trên từng replica…
-

Database 301: Materialized View
Trong SQL, chúng ta có thể sử dụng View như 1 dạng shortcut gọi tới câu lệnh truy vấn. Nội dung của View chính là kết quả thực thi của câu truy vấn đó. Materialized View cũng như vậy, tuy nhiên điểm khác biệt nằm ở chỗ: Materialized View có cache lại kết quả của…
-

Database 201: B-Tree
B-Tree là 1 kiến trúc index được mô phỏng dựa trên cấu trúc dữ liệu B-Tree, nhờ đó nó cũng được thừa kế tính năng lưu trữ cặp key-value dưới dạng có thứ tự. Điều này giúp cho nó có thể đáp ứng các loại truy vấn tìm kiếm key cũng như range query. Tuy…