
Nhắc lại ở các phần trước, ta đã được làm quen với những Hash Index, LSM-Trees Index hay B-Trees Index. Tuy nhiên, mình phải thú thực với các bạn rằng: tất cả các loại index đó đều chỉ phù hợp cho các hệ thống OLTP. Điểm khác biệt giữa OLTP và OLAP thì mình đã nhắc tới ở phần Database 302: OLTP hay OLAP? Chúng ta có thể khắc phục được phần nào bằng cách sử dụng kỹ thuật OLAP Cube kết hợp với Incremental Refresh Materialized View. Tuy nhiên, OLAP Cube cũng có những nhược điểm:
- Không linh hoạt, cần phải build lại Cube từ đầu nếu sửa cấu trúc/mô hình business
- Không realtime, định kỳ mới được update
- Thời gian build là rất lâu đối với những Cube lớn.
Những công việc trên tốn rất nhiều công sức và thời gian, nó phù hợp với cái thời đại những năm 1990-2000, tuy rằng vẫn thịnh hành cho tới ngày nay. Mọi chuyện đã khác rất nhiều vào năm 2010+, khi mà những thứ như bộ nhớ, tài nguyên tính toán đã trở nên rẻ hơn và mạnh hơn rất nhiều lần ngày trước. Nhờ đó Column-Oriented Storage đã được ra đời.
Column-Oriented Storage
Phần này, ta sẽ chỉ tập trung vào bảng Fact, vì nó là bảng chủ yếu chiếm nhiều bộ nhớ nhất và có số lượng bản ghi nhiều nhất trong cơ sở dữ liệu. Mặc dù bảng Fact thường có thể lên tới hàng trăm cột, tuy nhiên lúc thống kê ta lại chỉ cần dùng tới 3-4 cột trong số chúng. Ví dụ như này:
SELECT
dim_date.weekday, dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2013 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;Đối với các DB truyền thống, dữ liệu được tổ chức theo row-oriented: toàn bộ giá trị của 1 row được lưu trữ cùng nhau. Để có thể xử lý câu truy vấn phía trên, ta sẽ phải cài đặt index trên 2 cột fact_sales.date_key và fact_sales.product_sk: DB sẽ load hết toàn bộ dữ liệu (có thể lên tới hơn hàng trăm column) của những row thỏa mãn 1 trong những tiêu chí của mệnh đề WHERE, đẩy tất cả vào bộ nhớ, giải mã chúng và lọc bỏ đi những row không thỏa mãn điều kiện AND. Điều này sẽ tốn rất nhiều thời gian xử lý và có thể bị bottleneck khi load vào bộ nhớ.
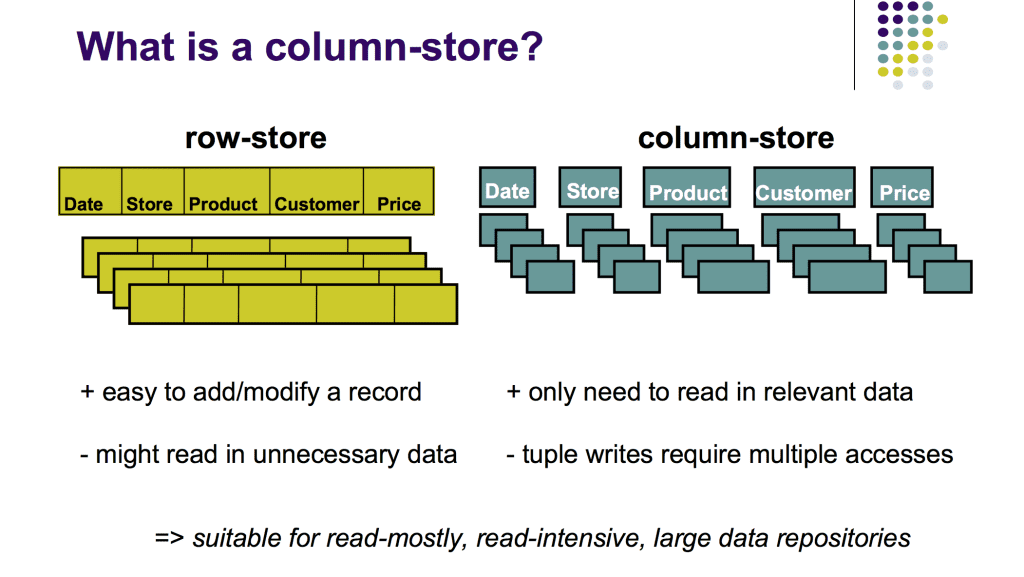
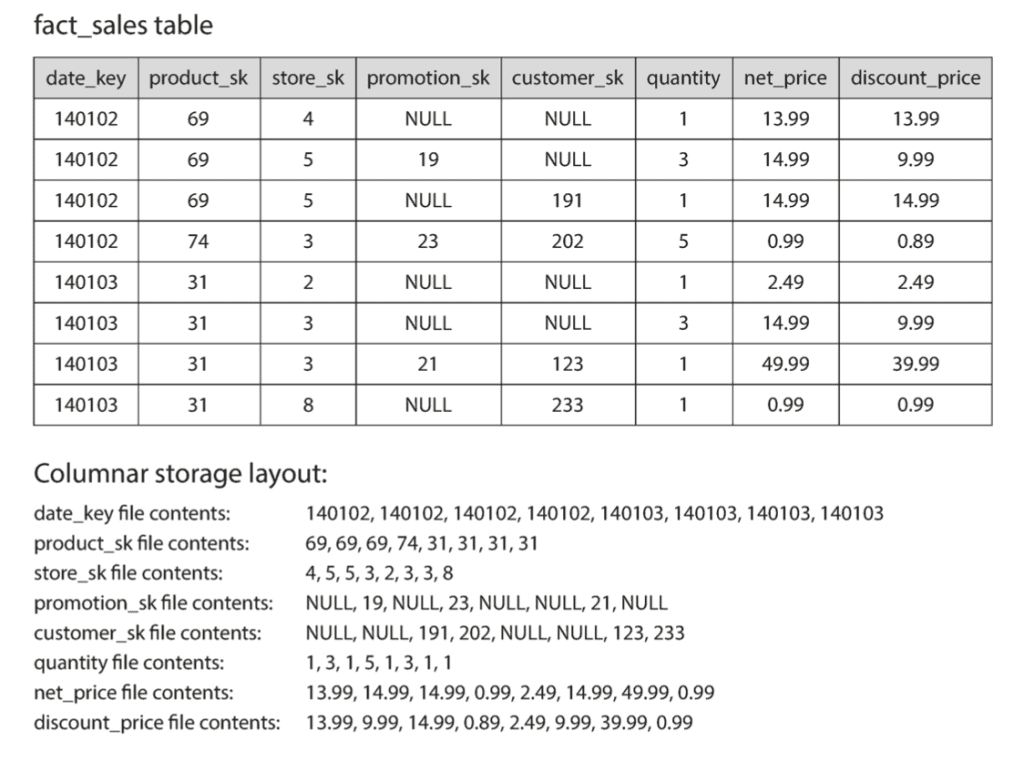
Ý tưởng của Column-Oriented Storage khá đơn giản: không lưu trữ toàn bộ dữ liệu trong 1 row cùng nhau, mà lưu trữ các giá trị của mỗi cột đó ra 1 nơi riêng. Khi đó, quá trình truy vấn sẽ chỉ cần đọc và giải mã những cột cần thiết, giúp tiết kiệm được rất nhiều công sức. Thứ tự của các giá trị trong column sẽ trùng khớp với thứ tự của row. Ví dụ như bên dưới:
Nén dữ liệu
Bên cạnh ưu điểm của việc load những cột cần thiết, ta còn có thể giảm được kha khá kích thước dữ liệu trên disk nhờ việc nén. Kỹ thuật nén hay được sử dụng đó là nén bitmap – mã hóa dưới dạng vector N giá trị (với N là số lượng bản ghi):

Với K giá trị unique thì ta sẽ phải lưu K cái vector bitmap như trên hình minh họa. Thông thường, khi N là rất lớn, vector của chúng ta sẽ có dạng là vector thưa. Khi đó, ta có thể chuyển nó về dạng Run-length encoding để tối ưu hơn nữa.
Mã hóa bitmap thực sự rất phù hợp với kiểu truy vấn của OLAP. Chẳng hạn như:
WHERE product_sk IN (30, 68, 69):
Load bitmap của 3 giá trịproduct_sk = 30,product_sk = 68, vàproduct_sk = 69, rồi thực hiện phép toán OR trên 3 cái bitmap đó => Thu được vector trong đó các vị trí có số 1 chính là vị trí thứ tự của bản ghi thỏa mãn.WHERE product_sk = 31 AND store_sk = 3:
Load bitmap của giá trịproduct_sk = 31vàstore_sk = 3, rồi thực hiện phép toán AND trên chúng. Nhờ vào việc “Thứ tự của các giá trị trong column trùng khớp với thứ tự của row” => Thu được vector trong đó các vị trí có số 1 chính là vị trí thứ tự của bản ghi thỏa mãn.
Ưu điểm của các phép OR và AND đó là nó có thể thực hiện trực tiếp ngay trên dữ liệu nén, mà không phải qua bước giải mã trước đó.
Ngoài ra, còn nhiều kiểu mã hóa khác nhau tương ứng với từng data type, ta sẽ không đi sâu thêm vào chi tiết phần đó. Có gì nếu quan tâm thì các bạn tham khảo thêm ở đây.
Ghi dữ liệu
Ta không thể sử dụng cách tiếp cận in-place update như B-Trees được, vì nếu như có 1 bản ghi mới được chèn vào giữa page, mình sẽ phải sửa lại thứ tự của toàn bộ các cột. Thật trùng hợp, ta vẫn có thể sử dụng các tiếp cận của LSM-Tree vào trong Column-Oriented Storage được.
- Đầu tiên, tất cả các lệnh ghi sẽ được xử lý ngay trong bộ nhớ. Ở đó, các bản ghi sẽ được sắp xếp sẵn (còn thứ tự gì thì tùy vào giá trị của các cột hoặc do mình tự cấu hình, làm sao để có thể nén được tối ưu nhất sau này).
- Khi bộ nhớ tới 1 ngưỡng nhất định, dữ liệu sẽ được ghi xuống disk với cấu trúc Column-oriented.
- Định kỳ sẽ có tiến trình compaction xử lý merge những file trong disk lại.
- Quá trình truy vấn sẽ được thực thi ở trên disk lẫn cả trong bộ nhớ, rồi sau đó kết hợp cả 2 lại.

Leave a Reply