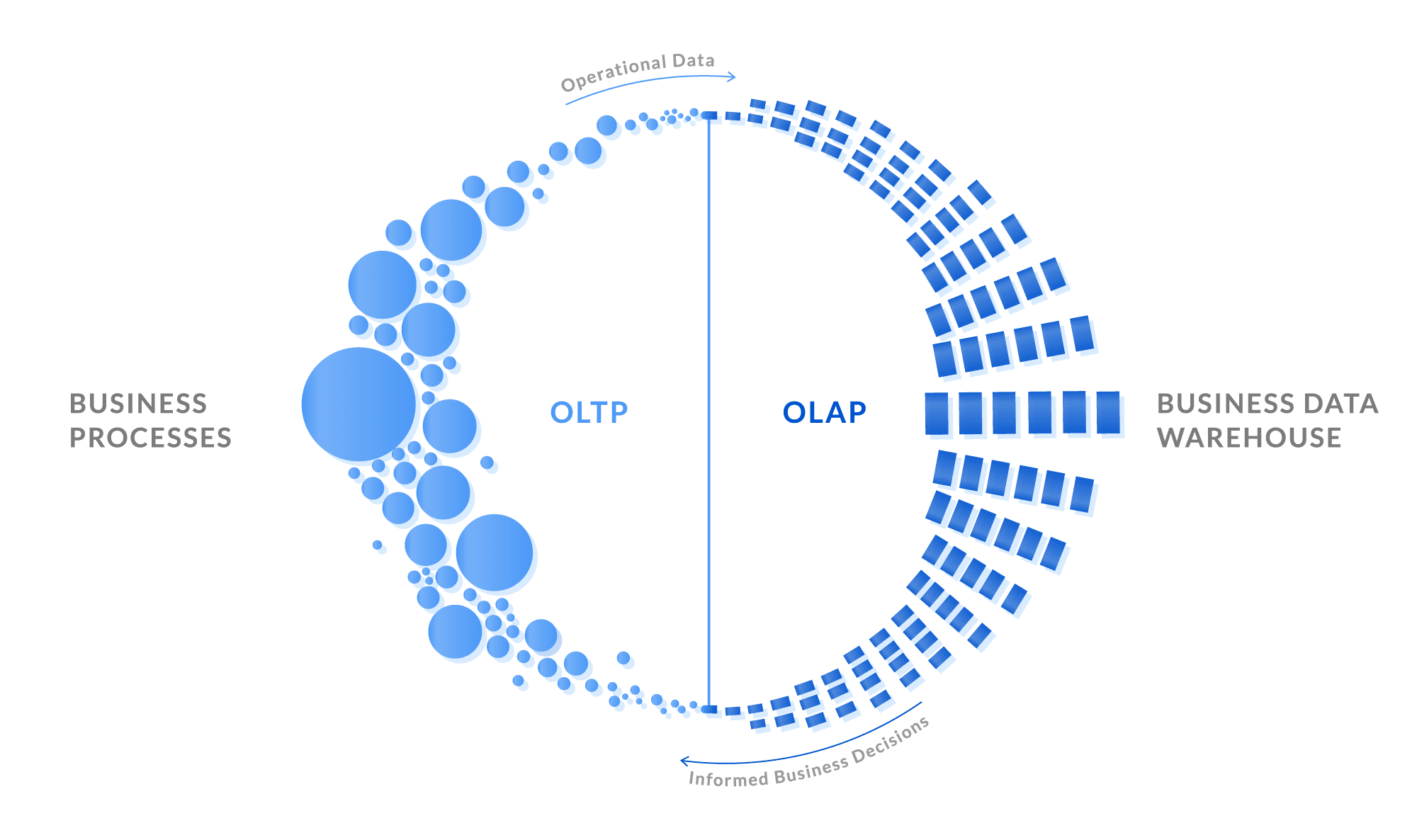
Trong những thời kỳ ban đầu thuở sơ khai, cơ sở dữ liệu chủ yếu chỉ được sử dụng cho các hoạt động giao dịch thương mại: bán các mặt hàng, order nhà cung cấp, trả lương cho nhân viên,… Và khi mà nó bắt đầu được phổ biến rộng rãi hơn cho nhiều lĩnh vực khác, thuật ngữ giao dịch (transaction) đã dần bị biến tướng: nó mang hàm ý là 1 đơn vị công việc logic (insert, update, delete, hoặc 1 nhóm gồm nhiều operation) có thể truy cập và sửa đổi nội dung của cơ sở dữ liệu.
Thuật ngữ OLTP (Online Transaction Processing) cũng được ra đời từ đây, hầu hết các ứng dụng kinh doanh đều là các hệ thống này. OLTP tập trung vào khía cạnh quan trọng nhất của nó, đó là các transaction (insert, update, delete) và chỉ cần tìm kiếm hoặc truy vấn trên 1 lượng key rất nhỏ mà thôi.
Dần dần, người ta bắt đầu khai thác dữ liệu có sẵn với mục đích làm báo cáo, thống kê để đánh giá và cải tiến mô hình kinh doanh,… Nhưng OLTP lại không phù hợp với ngữ cảnh đó: thông thường, việc truy vấn thống kê sẽ cần phải scan trên một khoảng dữ liệu rất rộng. Chưa kể tới việc nó không cần tới toàn bộ dữ liệu thô như OLTP, mà chủ yếu chỉ cần dùng tới một vài cột nhất định để sử dụng các phép gom như sum, average, count,…
Việc này đã dẫn đến 1 mô hình hệ thống mới được ra đời
OLAP
OLAP là viết tắt của Online Analytical Processing. Một hệ thống OLAP được dùng để phân tích dữ liệu một cách hiệu quả.
Không giống như OLTP, các hệ thống OLAP làm việc với một lượng dữ liệu rất lớn. Bảo đảm tính chính xác và tính toàn vẹn của các giao dịch không phải là mục đích của chúng; điều này trái ngược với OLTP. Các hệ thống OLAP có một nhóm người dùng nhỏ hơn so với các hệ thống OLTP, thường là những nhà phân tích hoặc quản lý. Ví dụ: bạn sẽ không tương tác với hệ thống OLAP của ngân hàng vì nó ghi lại các giao dịch tài khoản của bạn.
Hoạt động chủ yếu trong các các hệ thống OLAP là các truy vấn dữ liệu, chúng thường là các truy vấn lớn và chấp nhận cho phép mất nhiều thời gian để thực hiện. Ngược lại, các hệ thống OLTP sử dụng các lệnh phổ biến như INSERT, UPDATE, DELETE và yêu cầu là phải nhanh, không nên quá lâu.
Sau đây là tổng hợp những sự khác biệt giữa OLTP và OLAP:
| Transaction processing systems (OLTP) | Analytical systems (OLAP) | |
|---|---|---|
| Chủ yếu đọc | Số lượng nhỏ bản ghi, thường được quét bằng key | Tổng hợp dựa trên một lượng bản ghi cực lớn |
| Chủ yếu ghi | Trực truy, đòi hỏi tốc độ nhanh | Bulk import (ETL) hoặc sử dụng event stream |
| Được dùng bởi | Người dùng cuối, thông qua ứng dụng web hoặc app | Nhà phân tích nội bộ, hỗ trợ cho việc ra quyết định |
| Dữ liệu đại diện cho | Trạng thái hiện tại | Lịch sử các sự kiện đã diễn ra từ trước tới nay |
| Kích thước dataset | Gigabytes to terabytes | Terabytes to petabytes |
SQL tỏ ra là một ngôn ngữ khá là linh hoạt, nó đáp ứng được nhu cầu cơ bản của cả OLTP và OLAP. Chính vì vậy, thời gian đầu các doanh nghiệp vẫn thường chạy chung cả 2 trên cùng 1 cơ sở dữ liệu. Dần dần, họ nhận ra việc này dẫn tới việc suy giảm hiệu suất trầm trọng trên DB, ảnh hưởng tới hoạt động của người dùng cuối. Vào những năm 1990, đa phần các công ty đã dần chuyển sang chạy OLAP trên 1 cơ sở dữ liệu riêng (còn được gọi là data warehouse), tách biệt khỏi hệ thống OLTP.
Star schema
Mô hình chiều dữ liệu (Dimensional modeling) là một phần của thiết kế data warehouse, kết của trong việc tạo mô hình chiều. Có 2 loại bảng tham gia vào:
- Các bảng dimension được sử dụng để mô tả dữ liệu mà chúng ta muốn lưu trữ. Ví dụ: một nhà bán lẻ muốn lưu trữ thời gian, cửa hàng, và nhân viên tham gia vào một hoá đơn. Mỗi một bảng dimension là một danh mục của chính nó (ngày tháng, nhân viên, cửa hàng) và có thể có một hoặc nhiều thuộc tính (attributes). Với mỗi một cửa hàng, chúng ta lưu chúng các thông tin như vị trí trong thành phố, vùng miền, tỉnh thành và quốc gia. Mỗi một ngày tháng chúng ta lưu năm, tháng, ngày trong tháng, ngày trong tuần…Điều này liên quan đến sự phân cấp của các thuộc tính trong bảng dimension.
Trong sơ đồ ngôi sao, chúng ta sẽ thường tìm một vài thuộc tính là tập con của các thuộc tính khác trong cùng 1 bản ghi. Sự dư thừa này nên rất thận trọng và giúp tăng hiệu năng tốt hơn. Chúng ta có thể dùng ngày tháng, vị trí, và chi nhánh bán hàng để tổng hợp (chính là transform trong ETL) và lưu trữ dữ liệu trong DWH. Trong mô hình dimension, nó rất quan trọng trong việc định nghĩa dimension đúng và phù hợp.
- Bảng Fact chứa dữ liệu mà chúng ta muốn thêm vào reports, tổng hợp trên các giá trị trong các bảng dimension. Một bảng fact chỉ có các cột lưu giá trị và các cột khoá ngoại tham chiếu đến bảng dimensions. Kết hợp tất cả các khoá ngoại và khoá chính trong bảng fact. Ví dụ, một bảng fact có thể lưu trữ một số lượng các hợp đồng và số lượng các nhân viên bán hàng từ các danh sách hợp đồng.
Với các thông tin này chúng ta có thể hiểu và xây dựng được sơ đồ ngôi sao.

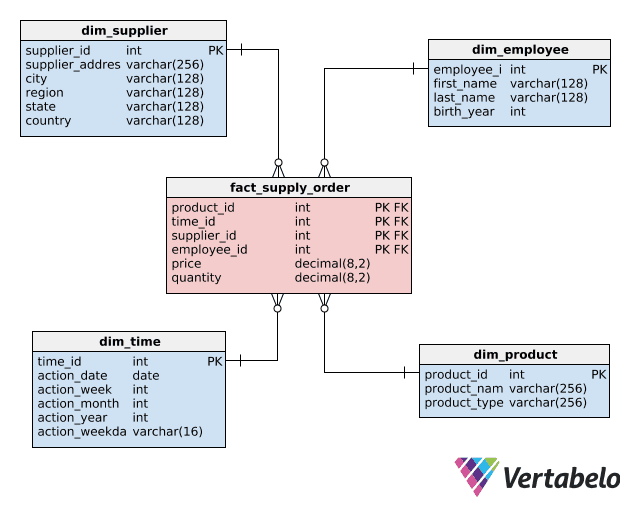
Ngoài ra, còn nhiều mô hình khác nữa ví dụ như Snowflake hay Galaxy,… Ở trong bài này mình sẽ không đi sâu vào chi tiết về chúng.
OLAP Cube
Một khía cạnh cần được quan tâm trong OLAP đó là: hầu hết các câu truy vấn thường liên quan tới các lệnh gom như COUNT, SUM, AVG, MIN, MAX,… và kết quả trả về thì có thể chấp nhận không cần quá chính xác. Như vậy, ta hoàn toàn có thể cache lại kết quả tính toán sau mỗi lần truy vấn, để tránh việc liên tục phải xử lý dữ liệu thô. Một cách để cache lại dữ liệu đó là sử dụng Materialized View, đã được hỗ trợ sẵn trên hầu hết các cơ sở dữ liệu quan hệ.
Mô hình lưu trữ thường được sử dụng có tên là OLAP Cube, là thuật ngữ dùng để chỉ dữ liệu có nhiều chiều. Nếu số chiều của dữ liệu lớn hơn 3, dữ liệu này còn được gọi là hypercube. Để cho dễ hình dung, ta có thể tưởng tượng 2 chiều nó là 1 bảng hình chữ nhật, và 3 chiều nó giống như 1 khối rubick lập phương, nhiều hơn nữa thì mình chịu, không diễn giải được bằng hình ảnh 😀
Mình minh họa bằng ví dụ đơn giản nhất là giả thiết rằng bảng Fact của chúng ta chỉ có 2 chiều thôi: date và product. Trong đó: trục dọc là date, và trục ngang là product. Mỗi ô trong bảng sẽ tương ứng với kết quả tính được của product và date tương ứng.
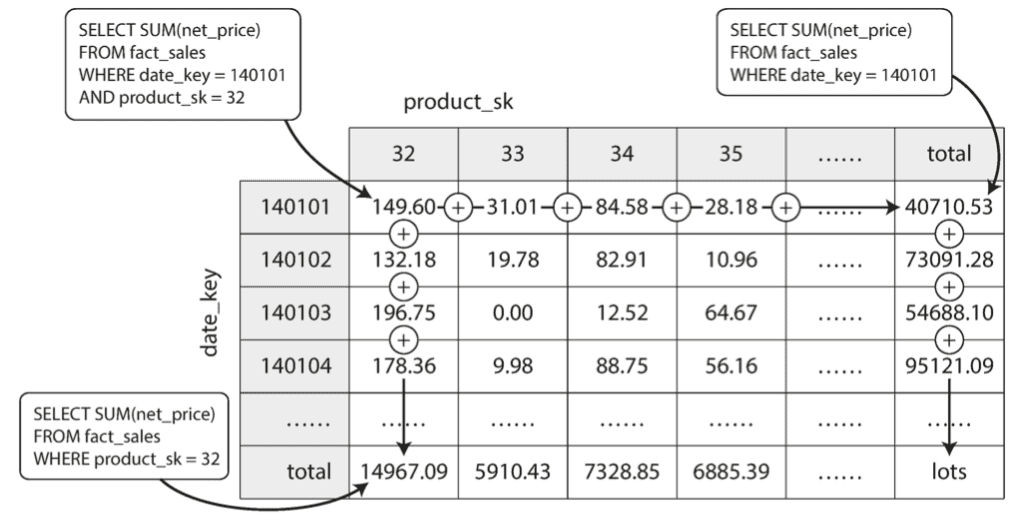
Ta nhận thấy rằng khi chạy gom (reduce) trên 1 dòng bất kỳ thì ta sẽ thu được tổng net_price thu được trong ngày hôm đó, và đồng thời gom trên 1 cột thì ta lại được tổng net_price của sản phẩm trong tất cả các ngày.
Thực tế, bảng Fact thường có nhiều hơn 2 dimension. Nhưng về nguyên tắc thì vẫn là giống nhau: mỗi cell sẽ là giá trị tổng hợp của tất cả các dimension tương ứng. OLAP Cube mà kết hợp cùng với Materialized View thì truy vấn sẽ rất nhanh, nhờ có kết quả đã được tính toán sẵn và lưu lại từ trước.
Thực hành OLAP Cube với PostgreSQL
Trong PostgreSQL, ta có thể sử dụng từ khóa CUBE để tạo ra nhiều group sets. Dưới đây là minh họa trực quan về group sets:
CUBE(e1, e2, e3)
(e1, e2, e3)
(e1, e2, *)
(e1, *, e3)
(e1, *, *)
(*, e2, e3)
(*, e2, e3)
(*, e2, *)
(*, *, e3)
(*, *, e3)Như vậy nếu trong CUBE mà chứa n cột thì ta sẽ có n^{2} group sets. Tiếp theo ta xem tới câu lệnh truy vấn minh họa:
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
CUBE (brand, segment)
ORDER BY
brand,
segment;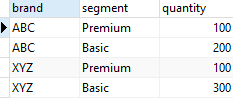
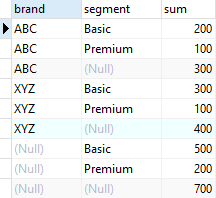
Để lưu kết quả này vào disk để tái sử dụng lại, ta bổ sung thêm Materialized View:
CREATE MATERIALIZED VIEW brand_segment_matview AS
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
CUBE (brand, segment)
ORDER BY
brand,
segment;
-- refresh
REFRESH MATERIALIZED VIEW brand_segment_matview;Vì Materialized View không tự động cập nhật lại kết quả khi có thay đổi ở bảng Fact, nên ta sẽ cần định kỳ gọi lệnh REFRESH MATERIALIZED VIEW [ CONCURRENTLY ]. Refresh trong PostgreSQL là Complete Refresh (tức là tính toán toàn bộ lại dữ liệu từ đầu), nên tốt nhất là ta nên chạy nó vào tầm nửa đêm.
OracleDB có hỗ trợ cơ chế Incremental Refresh – tức là chỉ cập nhật lại Materialized View dựa trên log thay đổi trên bảng Fact. Đối với những DB chưa hỗ trợ tính năng này, ta hoàn toàn cũng có thể tự implement lại nó: bằng cách lưu kết quả thống kê ban đầu vào 1 bảng, rồi cập nhật nó định kỳ dựa vào WAL của PostgreSQL hoặc Bin Log của MySQL.
Ở bài tiếp theo, chúng ta sẽ được biết tới 1 loại cơ sở dữ liệu khác chuyên biệt hơn dành cho OLAP: Database 303: Column-Oriented Storage.

Leave a Reply