Kafka hỗ trợ một nền tảng thông lượng cao (throughput), phân tán (distributed), có khả năng chịu lỗi (fault-tolerant) với việc phân phối thông điệp có độ trễ thấp. Vậy Kafka được thiết kế như thế nào để đạt được độ trễ thấp như vậy?
Hãy cùng tìm hiểu 3 cơ chế giúp Kafka đạt được điều này:
Batch data và Compression:
Tin nhắn có thể được viết và đọc vào queue theo batch. Giả sử chúng ta có 1000 tín nhắn, việc viết hoặc đọc 1000 tin nhắn 1 lần theo batch chắc chắn sẽ nhanh hơn nhiều nếu thực hiện cùng thao tác 1000 lần, mỗi lần 1 tin nhắn. Ngoài ra khi việc xử lý theo batch giúp ta có thể nén tin nhắn lại, giúp giảm dung lượng dữ liệu qua network.
Horizontally Scaling:
Kafka có khả năng có hàng nghìn partition cho một topic duy nhất, trải rộng giữa hàng nghìn máy. Điều này giúp Kafka có thể xử lý tải rất lớn.
Gửi tin nhắn có độ trễ thấp:
Hầu hết các hệ thống dữ liệu truyền thống sử dụng bộ nhớ truy cập ngẫu nhiên (RAM) để lưu trữ dữ liệu, vì RAM cung cấp độ trễ cực kỳ thấp. Tuy nhiên RAM rất đắt đỏ đặc biệt khi lượng dữ liệu là vô cùng lơn. Vì vậy, Kafka không dùng RAM để có thể gửi tin nhắn có độ trễ thấp, mà sử dụng 2 thiết kế là Sequential I/O và Zero Copy Principle.
Sequential I/O:
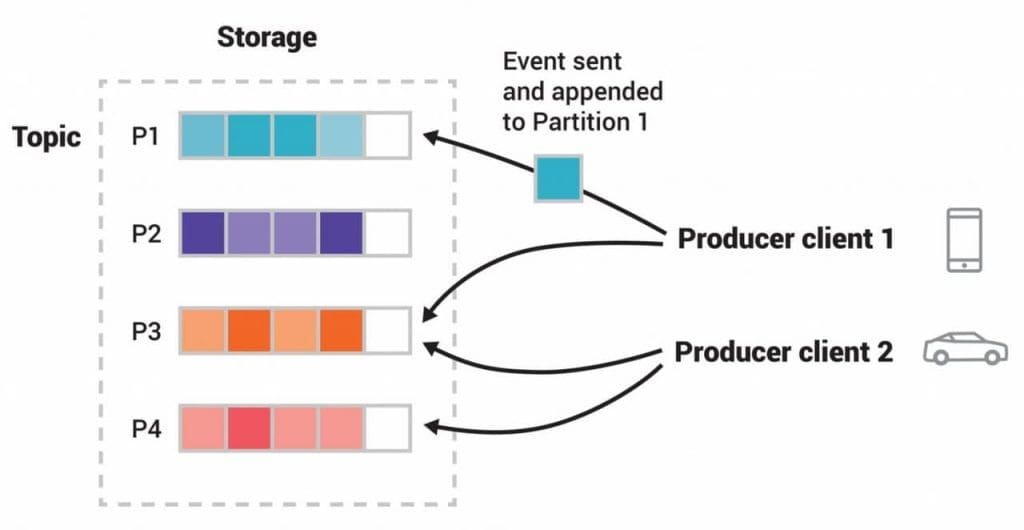
Kafka sử dụng filesystem để lưu trữ và cache tin nhắn. Chúng ta biết rằng disk chậm hơn nhiều so với RAM trong thời gian tìm kiếm thông tin được lưu trữ. Giống với Hash Index, Kafka giải quyết vấn đề này bằng việc sử dụng kỹ thuật Sequential I/O (với thiết kế append-only log, một cấu trúc dữ liệu có thứ tự). Giá trị offset tăng dần từ giá trị ban đầu 0, consumer luôn lưu trữ giá trị offset giúp việc tìm kiếm tin nhắn cần đọc trở nên nhanh hơn nhiều.
Zero Copy Principle
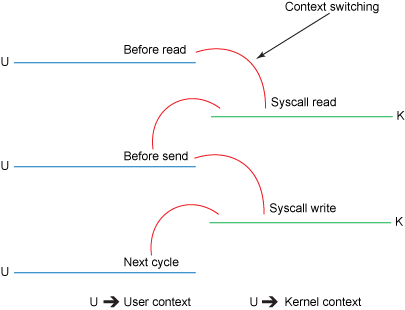
Để hiểu về kĩ thuật này, chúng ta cần hiểu điều gì xảy ra khi 1 ứng dụng muốn gửi dữ liệu từ disk qua 1 network. Theo cách truyền thống, dữ liệu sẽ được Kernal đọc và đẩy đến ứng dụng. Ứng dụng tiếp tục viết dữ liệu vào socket để sau đó gửi qua network:
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);Cách này đòi hỏi dữ liệu phải sao chép 4 lần để hoàn thành được quá trình. Chưa kể nó còn đòi hỏi CPU phải thực hiện 4 lần context switch giữa các thread:
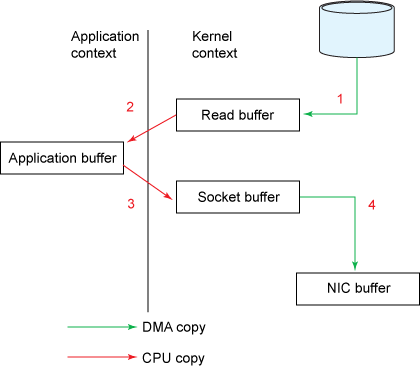
Với Zero Copy Principle, Kernal sẽ đọc dữ liệu trực tiếp dữ liệu từ disk và viết thẳng vào socket. Điều này giúp giảm thiểu các tác vụ trung gian và tối ưu hoạt động của Kernal.
Java có hỗ trợ sẵn cơ chế Zero Copy trên hệ điều hành Linux và UNIX thông qua method transferTo() trong class java.nio.channels.FileChannel. Ta có thể dùng method transferTo() để truyền tải dữ liệu dạng byte trực tiếp từ kênh đầu vào tới kênh đầu ra:
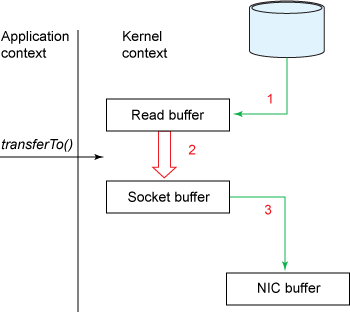
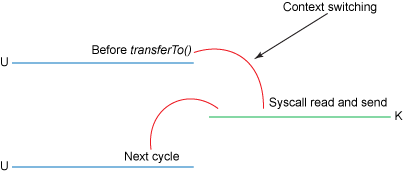
Như vậy, ta đã giảm được số lần context switch từ 4 xuống còn 2 lần, và số lần copy dữ liệu từ 4 còn 3 lần.
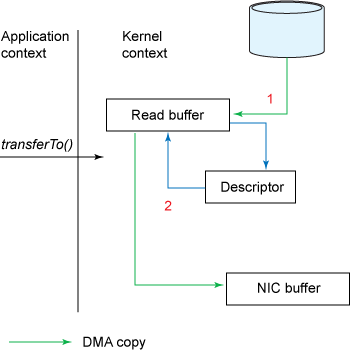
Bắt đầu từ Linux kernel 2.4 trở về sau, hệ điều hành đã cho phép copy trực tiếp dữ liệu từ kernel buffer tới network, không cần thông qua socket buffer nữa. Nhờ đó, ta giảm thêm được 1 lần copy nữa xuống chỉ còn 2 lần:
Leave a Reply