
System R là một trong những hệ thống cơ sở dữ liệu sớm nhất được xây dựng như một dự án nghiên cứu tại phòng thí nghiệm của IBM vào đầu những năm 1970. Với System R, lần đầu tiên SQL được triển khai và từ đó trở thành ngôn ngữ truy vấn dữ liệu quan hệ tiêu chuẩn như chúng ta đã thấy ngày nay.
Năm 1976, trong quá trình thử nghiệm xây dựng bộ tối ưu hóa truy vấn (query optimizer) cho System R, các kỹ sư của IBM đã vô tình phát hiện ra một lỗi logic thú vị, mang tính học thuật cao. Vì được phát hiện đúng vào ngày lễ Halloween, vấn đề này đã chính thức được đặt tên là Halloween Problem.
Vấn đề Halloween là gì?
Halloween Problem mô tả một tình huống trong đó một thao tác UPDATE có thể cập nhật cùng một bản ghi nhiều lần một cách không mong muốn, dẫn đến kết quả sai lệch. Nguyên nhân sâu xa đến từ sự tương tác giữa việc quét chỉ mục (index scan) và thay đổi vị trí của bản ghi trong chính chỉ mục đó.
Phân tích kịch bản ví dụ
Hãy cùng xem xét kịch bản kinh điển sau:
CREATE TABLE employees (id INT PRIMARY KEY, salary INT);
CREATE INDEX idx_salary ON employees(salary);
INSERT INTO employees (id, salary) VALUES
(1, 10000),
(2, 10500),
(3, 50000);Chúng ta thực hiện truy vấn tăng lương 10% cho tất cả nhân viên có lương dưới 25,000$:
UPDATE employees SET salary = salary * 1.1 WHERE salary < 25000;Các kỹ sư của IBM kỳ vọng kết quả sẽ như bên dưới:
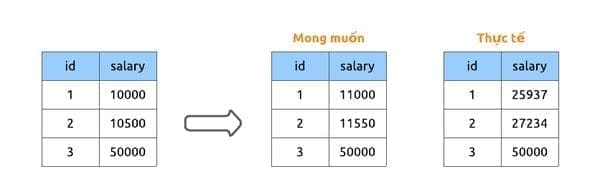
Tuy nhiên, thực tế cuối cùng thu được là tất cả nhân viên đều được nâng lương lên mức ≥ $25000.
Tại sao lại như vậy?
Quá trình UPDATE trong trường hợp này diễn ra tuần tự cho từng bản ghi thỏa mãn điều kiện WHERE:
- Tìm kiếm: Hệ thống sử dụng chỉ mục
idx_salary(dạng B-Tree) để quét các bản ghi cósalary < 25000. Do cấu trúc cây, các bản ghi có lương thấp nhất (id=1) sẽ được tìm thấy và xử lý trước. - Tính toán: Giá trị
salarymới được tính toán (10000 * 1.1 = 11000). - Ghi dữ liệu: Giá trị mới này được ghi vào bảng. Đồng thời, để duy trì tính toàn vẹn của chỉ mục, hệ thống phải cập nhật ngay lập tức vị trí của bản ghi trong chỉ mục
idx_salary. Hành động này khiến bản ghi id=1 “di chuyển” về phía bên phải trong cây B-Tree (vì giá trị salary từ 10000 đã tăng lên 11000, lớn hơn 10500 của id=2).
Quá trình này thực hiện tuần tự cho từng bản ghi và lặp lại tới khi không còn bản ghi nào thỏa mãn điều kiện WHERE được tìm thấy.
Điểm mấu chốt: Sau khi bản ghi id=1 được cập nhật và di chuyển trong chỉ mục, con trỏ quét (cursor) của truy vấn UPDATE (vẫn đang duyệt qua chỉ mục từ trái sang phải) sẽ gặp lại chính bản ghi id=1 này ở một vị trí mới. Hệ thống lại xác định nó thỏa mãn điều kiện salary < 25000 (vì 11000 < 25000) và thực hiện cập nhật lần thứ hai. Quá trình này tạo thành một vòng lặp vô hạn cho đến khi giá trị lương của cả hai bản ghi vượt qua ngưỡng 25,000$.
Các giải pháp khắc phục Halloween Problem
Các hệ quản trị cơ sở dữ liệu hiện đại đã phát triển nhiều kỹ thuật để ngăn chặn vấn đề này, trong đó phổ biến nhất là:
Buộc Sử dụng Scan Bảng (Table Scan): Trong một số trường hợp, optimizer có thể lựa chọn quét toàn bộ bảng thay vì sử dụng chỉ mục để tránh rủi ro, mặc dù điều này có thể kém hiệu quả hơn về mặt hiệu suất.
- Tách biệt Pha Đọc và Pha Ghi (Split Update): Thay vì cập nhật từng bản ghi một cách tuần tự, hệ thống sẽ thực hiện trong hai pha riêng biệt:
- Pha Đọc: Thực thi truy vấn
SELECTđể tìm tất cả các bản ghi thỏa mãn điều kiệnWHEREvà lưu trữ danh sách các khóa chính (Primary Key) hoặc Row Identifier (RID) này vào một vùng nhớ đệm tạm thời. - Pha Ghi: Dựa trên danh sách đã lưu, hệ thống tiến hành cập nhật giá trị cho từng bản ghi. Vì danh sách này là cố định và không bị ảnh hưởng bởi các thay đổi về chỉ mục trong quá trình cập nhật, mỗi bản ghi sẽ chỉ được cập nhật đúng một lần.
- Pha Đọc: Thực thi truy vấn
- Sử dụng Chỉ mục Bao phủ (Covering Index): Nếu truy vấn chỉ cập nhật các cột không nằm trong chỉ mục được sử dụng cho mệnh đề
WHERE, vị trí của bản ghi trong chỉ mục đó sẽ không thay đổi, từ đó tránh được vấn đề. - Buộc Sử dụng Scan Bảng (Table Scan): Trong một số trường hợp, optimizer có thể lựa chọn quét toàn bộ bảng thay vì sử dụng chỉ mục để tránh rủi ro, mặc dù điều này có thể kém hiệu quả hơn về mặt hiệu suất.
Kết luận
Halloween Problem không chỉ là một giai thoại lịch sử thú vị mà còn là một bài học quan trọng về thiết kế hệ thống cơ sở dữ liệu. Nó đã thúc đẩy sự phát triển của các thuật toán xử lý truy vấn an toàn và mạnh mẽ hơn. Ngày nay, hầu hết các hệ quản trị cơ sở dữ liệu như Microsoft SQL Server, Oracle, hay PostgreSQL đều đã tích hợp cơ chế để tự động phát hiện và ngăn chặn vấn đề này, giúp các nhà phát triển an tâm hơn khi thao tác với dữ liệu.
Bạn đọc có thể tìm hiểu và tham khảo loạt bài viết ở đây để rõ hơn về cách mà Microrsoft SQL Server xử lý Halloween Problem.

Leave a Reply