Trong quá trình phát triển phần mềm, cách dữ liệu được lưu trữ xuống file hoặc được truyền sang service khác dưới định dạng gì là vô cùng quan trọng. Thông thường, đối với những dữ liệu trên file, ta có chọn kiểu định dạng “native” được hỗ trợ sẵn bởi ngôn ngữ lập trình, chẳng hạn như: java.io.Serializable (Java), pickle (Python),… Ưu điểm của cách này là tốc độ đọc, ghi nhanh và cú pháp thân thiện, dễ dàng decode/encode dữ liệu.
Tuy nhiên, nó cũng bộc lộ rất nhiều nhược điểm:
- Hệ thống sẽ bị bó buộc, gắn chặt vào 1 ngôn ngữ lập trình nhất định, thậm chí là 1 phiên bản nhất định: service A dùng Java 8 thì service B cũng buộc phải dùng Java 8 (không thể dùng Java 11 nếu muốn giao tiếp với A).
- Định dạng không bảo đảm cho việc fully compatibility: Liệu khi model của bạn bỏ 1 field đi thì có đảm bảo được service vẫn giải mã được dữ liệu cũ?
Những nhược điểm này đã dẫn tới nhu cầu của tiêu chuẩn định dạng dữ liệu. Ngày nay ta có thể bắt gặp rất nhiều tiêu chuẩn, có thể kể đến như CSV, TSV, XML, JSON, Protocol Buffers (Protobuf), Thrift, Avro. Mỗi loại đều có ưu điểm, nhược điểm nhất định, và phù hợp với nhu cầu sử dụng khác nhau. Nhìn chung, chúng được chia làm 2 loại: textual format và binary format, ta sẽ cùng làm rõ hơn nhé!
Textual Format
Gồm các định dạng human-friendly như CSV, TSV, XML, JSON, hiểu nôm na là con người nhìn bằng mắt thường cũng có thể dịch được kiểu dữ liệu này.
- XML, JSON phù hợp cho dữ liệu không có cấu trúc (schema của mỗi record bên trong có thể khác nhau) hoặc không thể trải phẳng (gồm array, nested field). XML là 1 chuẩn cũ từ rất lâu đời rồi, và nó hơi over-complicated quá mức. Ngày nay, đa phần các ứng dụng đều sử dụng JSON.
- CSV hay TSV thường được sử dụng cho những dữ liệu có cấu trúc và đã được trải phẳng. Dòng đầu tiên (header) được dùng để chú thích tên field, các dòng còn lại là dữ liệu được ngăn cách giữa các cột bởi dấu phẩy hoặc ký tự tab. Điều này giúp cho kích thước của CSV/TSV nhỏ hơn so với XML và JSON, vì ta không cần phải khai báo lặp đi lặp lại tên field ở mỗi dòng.
Tuy nhiên, nhược điểm của Textual Format lại là nó quá khó hiểu đối với máy tính:
- Máy không thể tự phân biệt được
1là số hay là string, đòi hỏi can thiệp của con người ở trong code chương trình: đây chính là nhược điểm của XML. CSV, TSV, JSON đã khắc phục được vấn đề này bằng cách phân biệt1với"1". - Tuy vậy, chúng không thể xử lý được độ chính xác (precision) của số vô tỉ. Để có thể hiện thị về dạng con người có thể nhìn thấy được, những số vô tỉ thuộc kiểu Double (
3,141592653...) sẽ cần được cast xấp xỉ về Float (3,141593). Khi đọc ra, máy sẽ không thể dịch ngược được trở về như ban đầu, không phân biệt được đấy là số thập phân hữu hạn3,141593hay do thu được từ số vô tỉ xấp xỉ mà ra. - Textual Format gặp khó khăn trong việc mã hóa các loại string không phải Unicode (ví dụ như dữ liệu ảnh): có thể tạm khắc phục bằng cách sử dụng base64 để mã hóa binary string về dạng human-friendly. Tuy nhiên cách này làm tăng kích thước của dữ liệu lên 33%.
- CSV/TSV dễ có bug trong quá trình giải mã nếu trong dữ liệu gốc có chứa dấu phẩy, ký tự tab hoặc ký tự xuống dòng.
Khi nào thì nên sử dụng JSON?
Với sự phổ biến rộng rãi và ưu điểm human-friendly của JSON, nó thường hay được sử dụng để trao đổi dữ liệu giữa các tổ chức, các team khác nhau.
Binary Format
Với những trường hợp cần trao đổi dữ liệu nội bộ bên trong team/dự án, mối quan tâm về performance thường được đặt lên hàng đầu: làm sao để kích thước gói tin hơn, làm sao để parse dữ liệu nhanh hơn. Với dataset nhỏ, sự ảnh hưởng sẽ khó có thể quan sát được, tuy nhiên khi chạm tới tầm terabytes thì việc lựa chọn định dạng dữ liệu đúng đắn sẽ tạo ra sự khác biệt đáng kể.
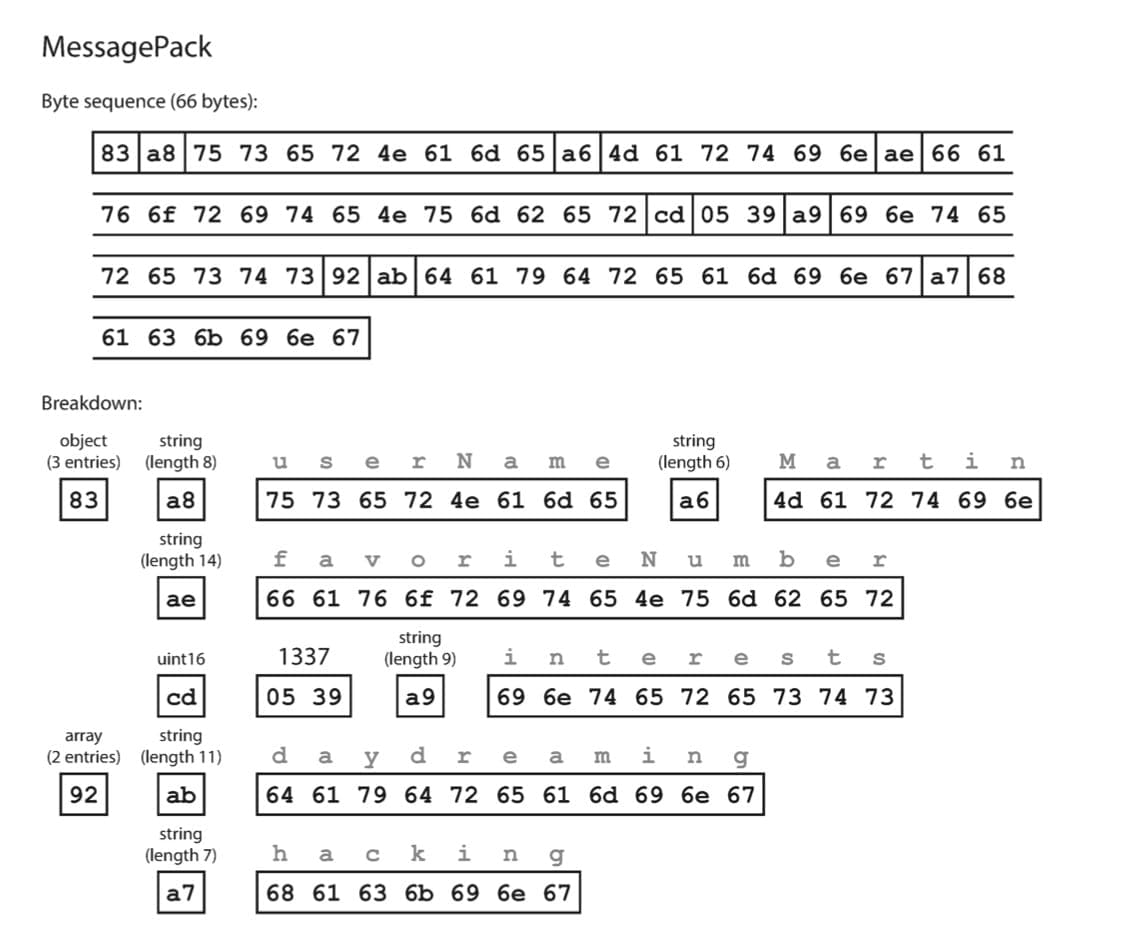
Để tránh việc các bạn bị ngộp, ta sẽ mở đầu phần này bằng việc cải tiến từ JSON trước. Hãy xem ví dụ message JSON sau:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Ta sẽ “ngầm” quy ước với nhau như sau:
- String: ký hiệu là
0xA0, cứ dài 1 ký tự thì tăng 1 bit. Ví dụ string gồm 1 ký tự là0xA1, 2 ký tự là0xA2, 3 ký tự là0xA3,… - Unsigned int16: ký hiệu là
0xCD. - Object: ký hiệu là
0x80, tương tự với String – cứ mỗi key (field) thì ta tăng 1 bit. Ví dụ object gồm 2 field sẽ được ký hiệu là0x82. - Array: ký hiệu là
0x90, tương tự với String – cứ mỗi phần tử thì ta tăng 1 bit. Ví dụ mảng 2 phần tử sẽ được ký hiệu là0x92.
Các bước mã hóa message trên về dạng binary:
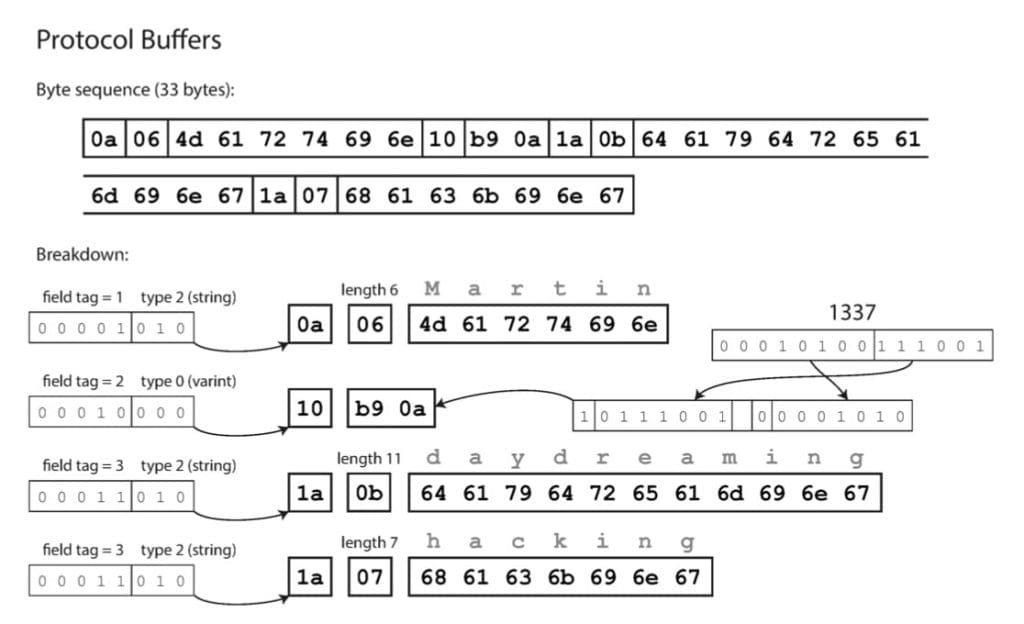
- Đầu tiên, message của chúng ta là 1 object gồm 3 field, nên ta sẽ bắt đầu bằng byte
0x83. - Field đầu tiên là
"userName"– 1 String gồm 8 ký tự, ta đánh dấu bằng byte0xA8rồi tiếp đến là 8 byte ký tự ASCIIu, s, e, r, N, a, m, e. - Giá trị của field đầu tiên là
"Martin"– 1 String gồm 6 ký tự, ta đánh dấu bằng byte0xA6rồi tiếp đến là 6 byte ký tự ASCIIM, a, r, t, i, n. - Lặp lại các bước 2 và 3 đối với 2 field còn lại
"favoriteNumber"và"interests", ta sẽ thu được 1 binary message kích thước 66 byte, tối ưu hơn so với định dạng JSON ban đầu (81 byte).
Plot twist: định dạng bên trên không phải do tôi tự bịa ra, mà nó có tên là MessagePack (chi tiết tham khảo tại đây nhé):
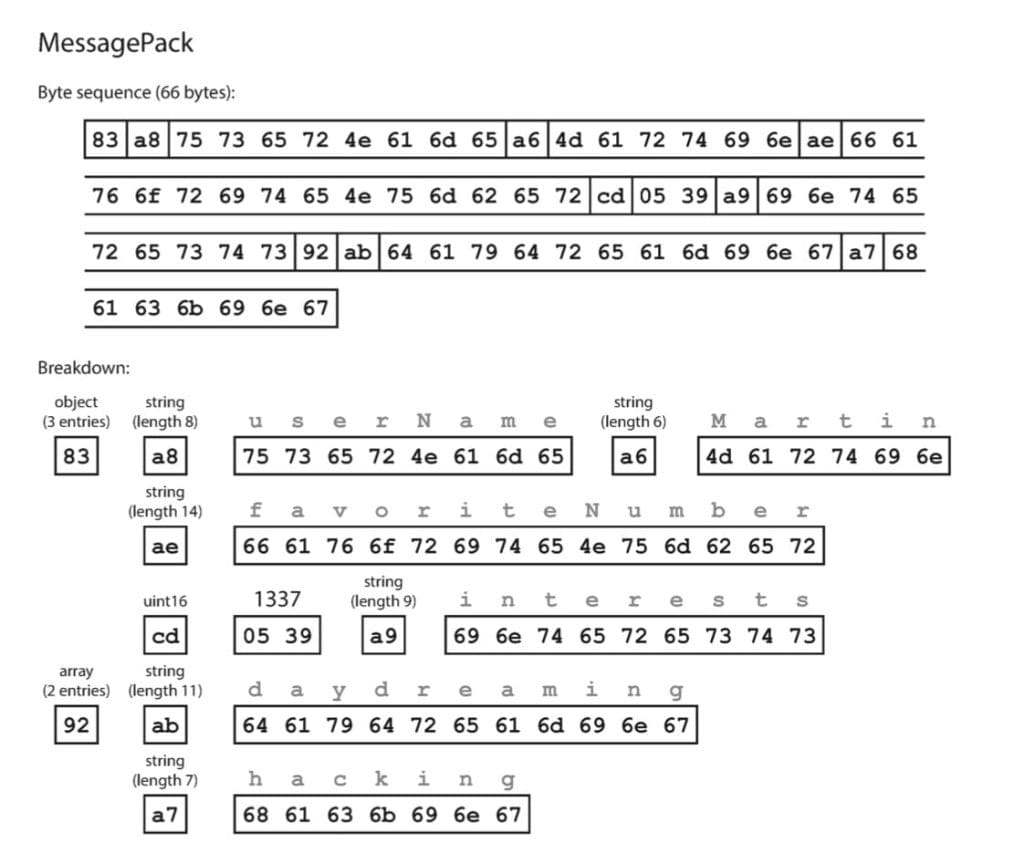
Ngoài ưu điểm tối ưu về kích thước, ta có thể nhận thấy rằng bên trong dữ liệu message có khai báo data type rất cụ thể, giúp cho máy tính có thể dễ dàng phân biệt được String hay số nguyên, số vô tỉ hay số thập phân hữu hạn,…
Thrift và Protobuf
Hãy nhớ lại tới hoàn cảnh sử dụng của Binary Format Message – đó là giao tiếp nội bộ trong team/dự án. Ta sẽ thấy việc khai báo field name ngay bên trong gói tin là không cần thiết, vì nó vốn được sinh ra để con người dễ dàng định danh các trường của dữ liệu. Ngược lại, máy tính không quan tâm tới cái field name ấy, do đó, để tối ưu hơn nữa, người ta sẽ đánh dấu field bằng số thứ tự 1, 2, 3,…N. Cụ thể field 1 tên là gì, field N tên là gì thì sẽ được khai báo ở Schema thay vì nhét vào nội dung message.
Apache Thrift và Protocol Buffers (hay còn gọi là Protobuf) dựa trên 1 nguyên lý giống nhau – đều yêu cầu bên đọc và bên ghi phải khai báo schema, chỉ khác nhau đôi chút ở phần tiểu tiết. Protobuf được phát triển bởi Google, được sử dụng trong GRPC, còn Thrift được phát triển bởi Facebook. Cả 2 cùng được công bố open source vào năm 2007-08, và có cú pháp khai báo Schema khá là tương đồng nhau:
Thrift
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}Protobuf
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}Thrift và Protobuf đều cung cấp tool hỗ trợ generate POJO class từ Schema để ta tiện cho việc lập trình. Mình sẽ cùng ngó qua chi tiết bên dưới chúng mã hóa dữ liệu như thế nào nhé!
Thrift BinaryProtocol
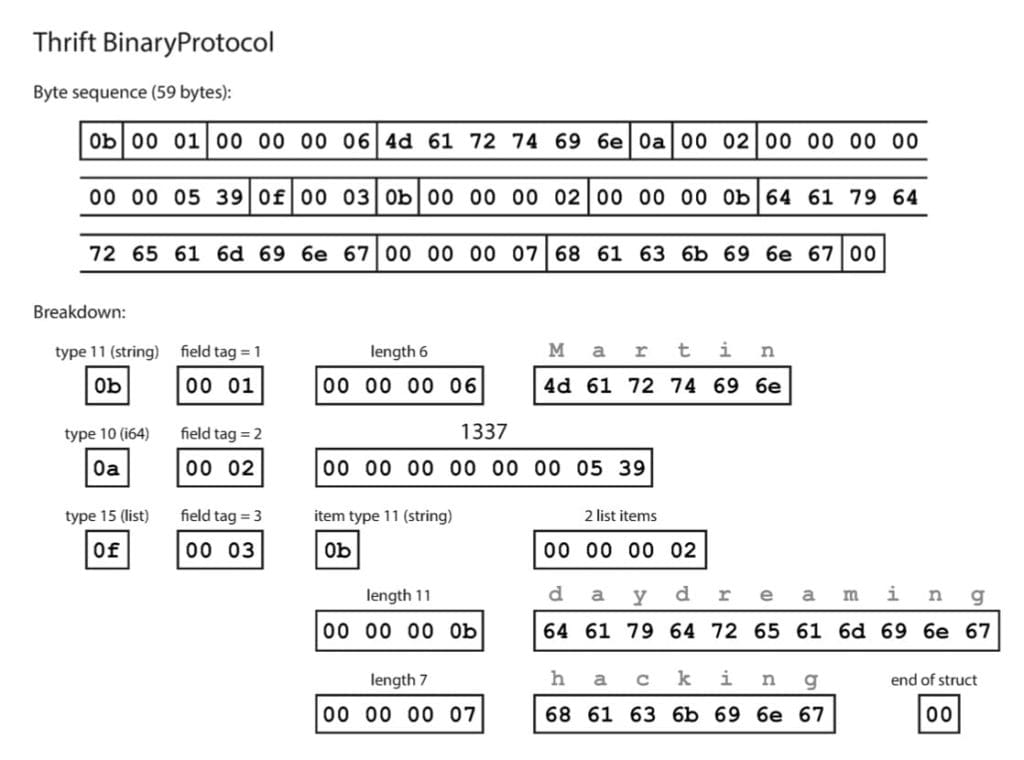
Có thể thấy nhờ vào việc cắt bỏ đi được field name, ta đã bắn một mũi tên trúng hai đích:
- Kích thước gói tin giảm đi đáng kể.
- Bù đắp phần cắt giảm vào những việc có ích hơn:
- Array ở trong MessagePack được ký hiệu bởi 1 byte trong đoạn từ
0x90cho tới0x9F: tức là tối đa chỉ được 15 phần tử. - Kích thước của array trong Thrift BinaryProtocol được mã hóa bằng 4 byte: tương đương với tối đa 232 phần tử.
- Array ở trong MessagePack được ký hiệu bởi 1 byte trong đoạn từ
Nhược điểm của cách này đó là giới hạn số lượng field bởi 2 byte (tương đương với 216 field).
Thrift CompactProtocol
Ta khắc phục nhược điểm trên bằng cách chỉ mã hóa giá trị delta giữa field id mà thôi:
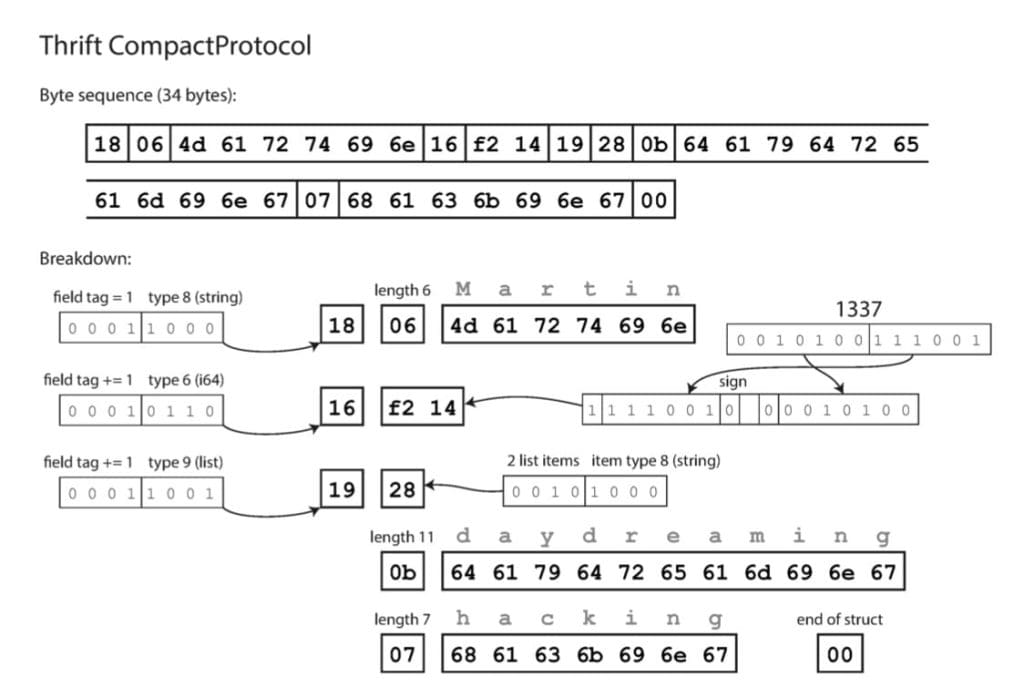
Thrift CompactProtocol mã hóa mỗi field dưới 1 trong 2 dạng sau:
- Short form: Delta field id được mã hóa bằng 4 bit (tối đa là 15 đơn vị), với cách này ta sẽ không bị giới hạn bởi số lượng field nữa. Data type cũng được rút ngắn xuống còn 4 bit, gộp chung với delta field id. Như vậy ta đã giảm được 3 byte của mỗi field xuống còn 1 byte.
- Long form: trong trường hợp có nhiều hơn 15 field bị bỏ trống, lúc này phần Delta sẽ fill bằng 0, và Thrift lưu thêm mã hóa field id dưới định dạng Little Endian. Field id càng lớn thì càng tốn nhiều byte (tối đa 3 byte).
Compact protocol field header (short form) and field value:
+--------+--------+...+--------+
|ddddtttt| field value |
+--------+--------+...+--------+
Compact protocol field header (1 to 3 bytes, long form) and field value:
+--------+--------+...+--------+--------+...+--------+
|0000tttt| field id | field value |
+--------+--------+...+--------+--------+...+--------+
dddd: delta field id
tttt: data typeSố nguyên trong Thrift CompactProtocol được mã hóa dưới định dạng Little Endian thay vì Big Endian. Chi tiết các bước convert từ hệ thập phân sang Little Endian của Thrift thì các bạn có thể tham khảo tại đây:
50399 = 1100 0100 1101 1111 (Big Endian representation)
= 00000 1100 0100 1101 1111 (Left-padding)
= 0000011 0001001 1011111 (7-bit groups)
= 00000011 10001001 11011111 (Most-significant bit prefixes)
= 11011111 10001001 00000011 (Little Endian representation)
= 0xDF 0x89 0x03Little Endian có những ưu điểm sau:
- Đọc số nguyên nhanh hơn so với Big Endian
- Tiết kiệm kích thước hơn: chẳng hạn như số trong đoạn [-64, 63] sẽ chỉ tốn 1 byte thay vì full 8 byte; trong đoạn [-8192, 8191] thì chỉ cần 2 byte. Số càng nhỏ thì càng tốn ít byte, rất linh hoạt.
- Nó sẽ rất thích hợp nếu chúng ta cần ép kiểu, ví dụ từ
intthànhlong:- Với giả định
intlà 4 byte,longlà 8 byte, nếu dùng Little Endian, khi ép kiểu, địa chỉ bộ nhớ không cần phải thay đổi. - Nhưng nếu cũng trường hợp đó, mà sử dụng Big Endian, thì chúng ta sẽ phải dịch địa chỉ bộ nhớ hiện tại thêm 4 byte nữa mới có không gian để lưu trữ.
- Với giả định
Thrift CompactProtocol thực sự rất hiệu quả, giúp giảm kích thước từ 66 (MessagePack) -> 59 (Thrift BinaryProtocol) -> 34 byte (Thrift CompactProtocol). Giới hạn duy nhất của nó nằm ở 4 bit delta field id: nếu bị bỏ trống vượt quá 15 field liên tiếp, ta sẽ phải sử dụng dạng long form, không tối ưu bằng short form.
Protobuf
Tương tự, Protobuf cũng sử dụng field id và Little Endian. Tuy nhiên nó không sử dụng delta field id, và không tồn tại kiểu array. Thay vào đó là kiểu repeated – tuy khá tương đồng với array về mặt interface, nhưng bản chất implement mã hóa bên dưới là khác nhau:
Trong điều kiện thuận lợi, Protobuf và Thrift ngang nhau về kích thước. Tuy nhiên vào tình huống xấu nhất nó gặp phải những nhược điểm sau:
- Càng nhiều field thì kích thước của Protobuf càng lớn.
- Càng nhiều phần tử repeated thì kích thước của Protobuf càng lớn.
Schema Evolution
Thực tế, dữ liệu của chương trình luôn có nhu cầu cần thay đổi schema (còn được gọi là schema evolution). Cách mà Thrift cũng như Protobuf xử lý việc này mà vẫn đảm bảo backward và forward compatibility là gì?
Field được định danh bởi tag id, và được chú thích với datatype. Ta có thể thay đổi tên field thoải mái, vì dữ liệu được mã hóa không đề cập tới nó. Nhưng ta không thể thay đổi field tag id, vì điều đó sẽ làm cho toàn bộ dữ liệu hiện tại đều bị sai.
Bổ sung field, ta cần cung cấp tag id mới. Code cũ khi đọc dữ liệu ra sẽ bỏ qua field đó vì tag id không nằm trong schema, lúc này datatype trong gói tin được sử dụng để tính toán chương trình cần skip qua bao nhiêu byte -> Thỏa mãn forward compatibility: code cũ có thể đọc được bản ghi viết bởi code mới.
Một chi tiết khi bổ sung field mới, ta không nên đánh dấu field là required. Tốt nhất mình nên đánh dấu nó là optional hoặc phải có giá trị mặc định (default value). Nhờ đó, dữ liệu được viết bởi code cũ sẽ vẫn hợp lệ đối với code mới -> Thỏa mãn backward compatibility.
Xóa field cũng tương tự với bổ sung field, ta chỉ có thể xóa field optional hoặc có giá trị mặc định, ngoài ra tag id của nó phải bị cấm hoàn toàn, không bao giờ được sử dụng trở lại.
Avro
Apache Avro là một định dạng dữ liệu binary với tư tưởng khác hoàn toàn so với Protobuf và Thrift. Nó được phát triển vào năm 2009 để phục vụ cho dự án Hadoop, sau khi thấy Thrift không thực sự phù hợp với nhu cầu của Hadoop.
Ta có thể khai báo schema của Avro bằng 1 trong 2 định dạng sau, chọn cái nào cũng được:
Avro IDL
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}JSON
{
"type": "record",
"name": "Person",
"fields": [
{
"name": "userName",
"type": "string"
},
{
"name": "favoriteNumber",
"type": [
"null",
"long"
],
"default": null
},
{
"name": "interests",
"type": {
"type": "array",
"items": "string"
}
}
]
}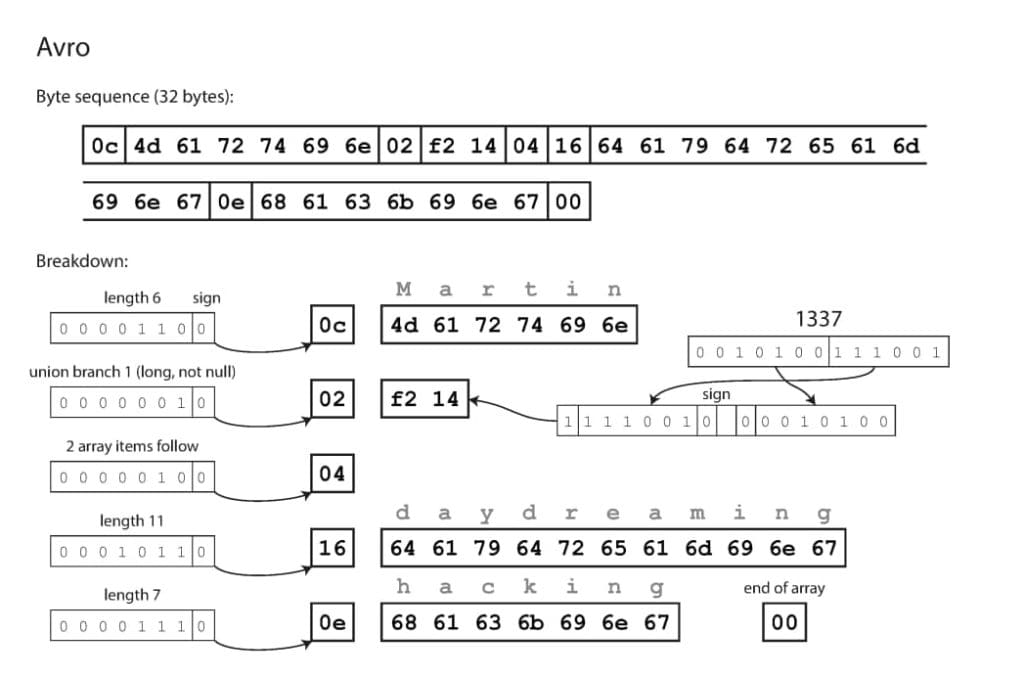
Định dạng Avro thu được kích thước bản ghi nhỏ nhất, chỉ 32 byte: hoàn toàn không hề có field tag id hay datatype ở trong dữ liệu binary.
- Mặc định trong Avro mỗi field đều là required. Trong trường hợp cần đánh dấu optional field, ta sẽ khai báo kiểu
Union[null, T]và cần dùng 1 byte để đánh dấu datatype của nó là null hay làT. - Đối với những datatype không cố định kích thước như string, array: cần 1 byte để lưu trữ độ dài.
- Các field được ghi vào theo đúng thứ tự đã được khai báo trong schema -> điều này đồng nghĩa với việc chương trình ở phía read chỉ có thể dịch được dữ liệu nếu nó biết schema lúc ghi.
Cách Avro hỗ trợ schema evolution
Khi chương trình mã hóa dữ liệu, nó đồng thời đính kèm cả schema vào bên trong gói tin. Ở phía bên đọc ra, thư viện sẽ đối chiếu giữa schema đính kèm trong gói tin với schema hiện tại, thực hiện đối chiếu lại để có thể dịch được bản ghi. Thứ tự các field bên trong schema đọc và ghi không cần phải giống nhau, bởi vì thư viện sử dụng field name để làm định danh, thay vì tag id như Protobuf hay Thrift. Dưới đây là minh họa cách Avro xử lý schema resolution:
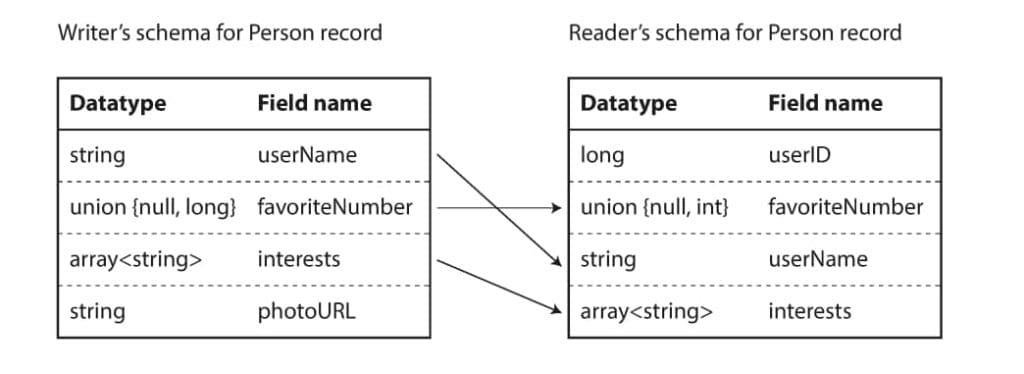
Chi tiết về Forward và Backward Compatibility có thể xem thêm tại đây và đây.
Khi nào thì nên dùng Avro?
Tới đây ta có thể cảm thấy hơi sai sai: nhúng schema vào trong gói tin, vậy thì kích thước dữ liệu sẽ rất lớn, chứ đâu có nhỏ như Protobuf với Thrift. Vậy tại sao Avro lại được chọn sử dụng trong Hadoop thay vì Thrift? Và những hoàn cảnh như nào thì nên sử dụng Avro? Dưới đây là một số ví dụ điển hình:
- File lớn chứa rất nhiều bản ghi: đây chính là cách mà Hadoop đang sử dụng Avro. Bên trong mỗi file có thể chứa hàng triệu bản ghi, được mã hóa với cùng 1 schema. Với cách này, ta chỉ cần đính kèm schema một lần duy nhất vào đầu mỗi file.
- Database: schema của bảng có thể bị thay đổi (add column, delete column, change datatype,…). Với Avro, khi bản ghi được lưu trong database, nó sẽ đính kèm thêm thông tin version number của schema. Danh sách lịch sử các schema được database lưu trữ lại dưới background, không thể bị sửa đổi.
- Truyền message qua 1 network connection: 2 đầu có thể trao đổi thông tin schema cho nhau ngay từ lúc thiết lập kết nối, và sử dụng schema đó trong toàn bộ vòng đời của connection.
- Message Queue: điển hình như Kafka, bản chất của consumer là đọc theo mini-batch (tức là poll đủ N bản ghi, hoặc cho tới khi vượt quá timeout) -> có thể đính kèm schema vào vị trí bắt đầu của mỗi batch.
Ưu điểm khác của Avro so với Protobuf và Thrift
Điểm khác biệt của Avro chính là không sử dụng tag id, điều này giúp cho nó có thể linh hoạt trong việc tự generate schema. Chẳng hạn như sau:
- Xuất dữ liệu ra 1 file chứa Avro schema và các bản ghi trong bảng. Tên cột tương ứng với tên field trong schema.
- Sau đó, ta thêm/xóa cột trong bảng rồi export lại. Lúc này 2 file Avro cũ và mới hoàn toàn có thể tương thích với nhau, vì chúng được map với nhau thông qua tên field.
- Ngược lại, nếu dùng Thrift hay Protobuf, ta sẽ cần phải gán field tag id bằng tay: mỗi lần database schema thay đổi, 1 người admin sẽ phải đứng ra để cập nhật ánh xạ từ tên cột sang field tag id. Quá trình này không thể diễn ra 1 cách tự động được như Avro.

Leave a Reply