Hiện nay, mỗi Database đều sử dụng phương pháp Isolation khác nhau. Thậm chí cũng có chuyện cùng một ý tưởng nhưng mỗi người lại triển khai khác nhau: cái thì chạy nhanh hơn, cái thì lại tốn ít bộ nhớ hơn, thậm chí cái còn có bug… Về cơ bản thì hiện nay có 4 tiêu chuẩn Transaction Isolation trong Database, và mỗi chúng nó sẽ giải quyết được các độ khó Concurrency Control khác nhau:
| Dirty Write | Dirty Read | Read Skew | Lost Update | Write Skew | Phantoms | |
|---|---|---|---|---|---|---|
| Read Uncommitted | ✓ | ✕ | ✕ | ✕ | ✕ | ✕ |
| Read Committed | ✓ | ✓ | ✕ | ✕ | ✕ | ✕ |
| Repeatable Read | ✓ | ✓ | ✓ | — | — | — |
| Serializable | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
✕ = bị lỗi
— = tùy từng trường hợp và giải pháp sử dụng
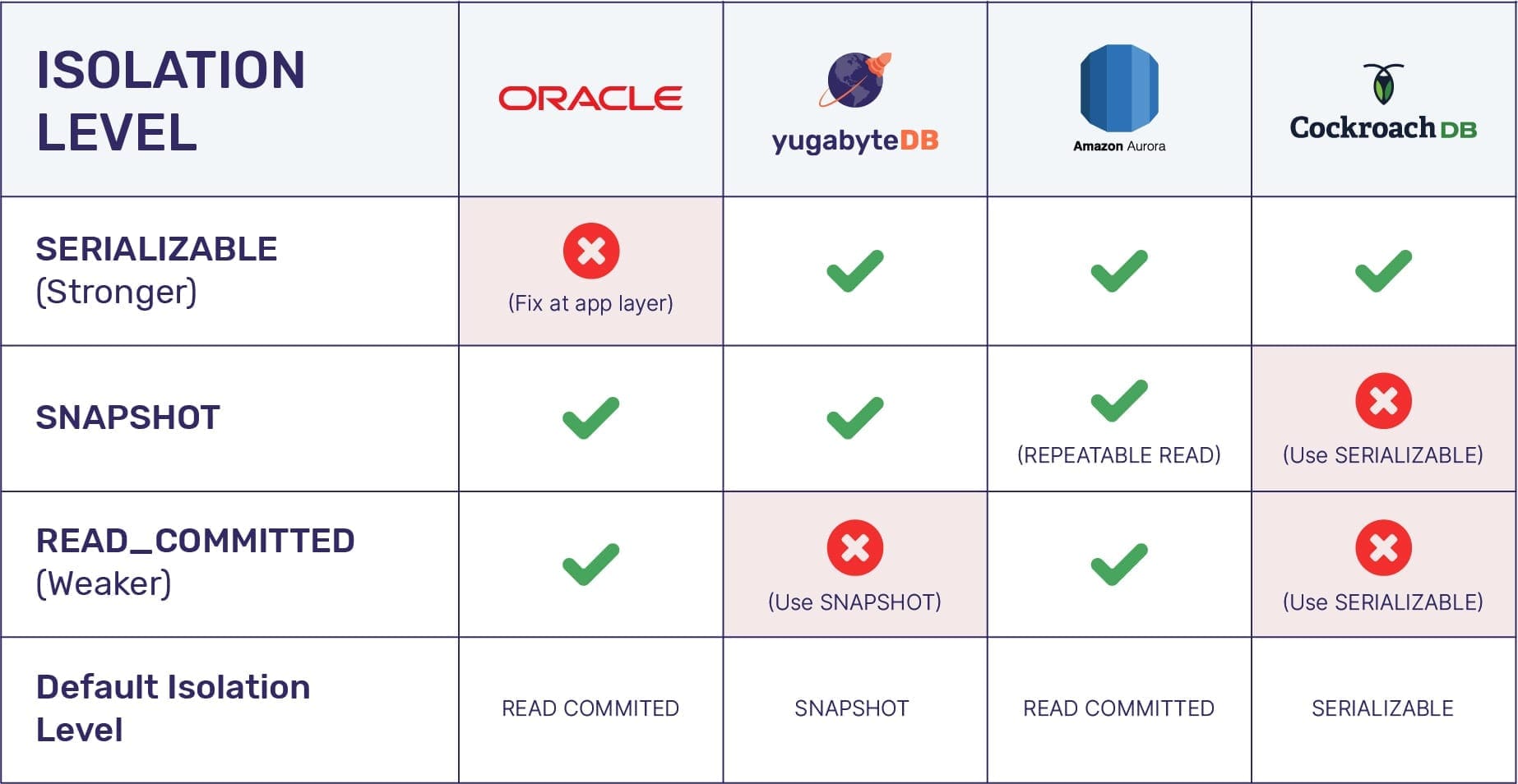
Đây là tiêu chuẩn chung, vốn đã được thống nhất từ trước tới nay. Tuy nhiên, mỗi Database nó lại tự đặt ra những cái tên khác nhau (không rõ vô ý hay cố tình). Đáng chú ý như:
- Mức Serializable của OracleDB bản chất là đang sử dụng Snapshot Isolation – giải pháp này được đánh giá là mới chỉ thuộc tiêu chuẩn Repeatable Read mà thôi.
- SQL Server có tới tận 6 mức độ isolation.
- Chi tiết hơn thì anh em xem tại đây: https://github.com/ept/hermitage
1. Read Uncommitted
Đây là mức độ cơ bản nhất, có thể dùng để chống lỗi Dirty Write. Nó khá là lightweight, chỉ acquire lock khi gọi Write Operation, và release lock khi transaction kết thúc (được commit hoặc rollback). Điều này đồng nghĩa với việc mỗi row trong 1 thời điểm chỉ có 1 transaction được quyền write tới nó.
How bad is Read Uncommited?
Nhìn chung thì Read Uncommitted cũng không quá tệ nếu ta biết cách sử dụng đúng lúc đúng chỗ, vì đối với các hệ thống lớn thì việc Write đúng quan trọng hơn Read đúng rất nhiều. Một sai sót nhỏ trong việc ghi có thể dẫn tới việc dữ liệu không thể khôi phục chính xác lại được, còn Read sai thì chỉ cần refresh lại giao diện hoặc fix code là xong.
Thay vì cố vạch ra các nhược điểm của Read Uncommited, sao chúng ta không thử làm ngược lại nhỉ? Hãy thử ngẫm nghĩ về câu hỏi bên dưới này trước khi bước sang phần kế tiếp nhé:
How much worse than locking read committed isolation is it?
https://sqlperformance.com/2015/04/t-sql-queries/the-read-uncommitted-isolation-level
2. Read Committed
2.1. Shared Lock
Cải tiến từ Read Uncommited, ta bổ sung thêm acquire lock kể cả khi gọi Read Operation (nhưng chỉ là shared lock). Khác với exclusive lock, shared lock sẽ được release ngay khi hoàn thành Operation. Cách tiếp cận này giúp cho ta đảm bảo những thay đổi của row sẽ phải chờ được commit/rollback thì mới được phép sẵn sàng available to read.
- Ban đầu khi transaction A muốn đọc 1 row, nó sẽ acquire lock và release nó ngay sau khi hoàn thành read operation. Tuy nhiên lock này ở chế độ share mode (tức là nhiều transaction cùng có thể cùng acquire và hold nó).
- Khi transaction B muốn ghi vào row, lock sẽ upgrade lên chế độ exclusive mode. Quá trình upgrade này chỉ được diễn ra khi tất cả các transaction khác đã release khỏi lock đã. Sau đó B sẽ acquire exclusive lock.
- Không transaction nào khác được phép acquire exclusive lock trong lúc lock vẫn chưa release.
Cách làm này có nhược điểm là hiệu suất bị chậm do phải acquire lock mỗi lần read. Nếu đa phần các request của ứng dụng là read, rất hiếm khi xuất hiện write request thì điều này thực sự gây lãng phí không cần thiết.
2.2. Consistent Read
Hướng tiếp cận thứ hai là sử dụng multi-version concurrency control: ngoài giá trị đã được commit là stable version, ta lưu thêm cả giá trị chưa được commit nữa (nếu có). Vì tối đa trong một thời điểm sẽ chỉ có 1 transaction được quyền write vào row cho nên ta sẽ chỉ có 1 latest version thôi. Tổng cộng là có 2 version.
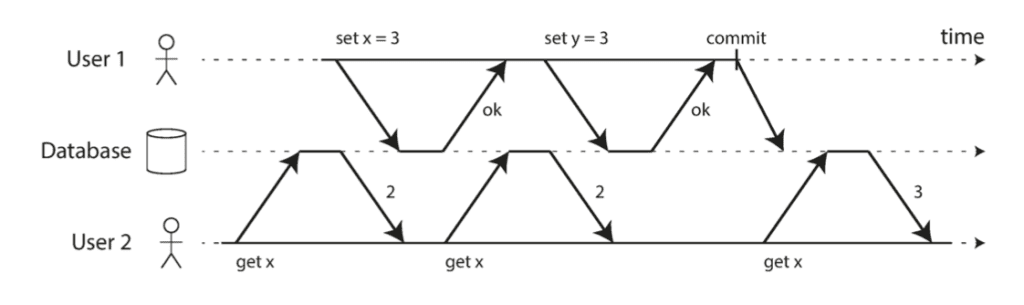
Như vậy, khi 1 transaction tiến hành ghi vào row, nó sẽ acquire lock và đánh dấu version mới cho bản ghi. Trong lúc transaction chờ được commit/rollback thì các thread khác hoàn toàn vẫn có thể vô tư read stable version của row mà không phải chờ mở lock nữa.
Read Committed giải quyết được vấn đề Dirty Read, tuy nhiên vẫn còn rất nhiều các lỗi khác chưa được xử lý: Read Skew (Non-repeatable Read), Lost Update, Phantom Read, Write Skew,...
3. Repeatable Read
Level này ám chỉ những phương pháp có khả năng giải quyết được bài toán Read Skew (hay còn gọi là Non-repeatable Read). Ngoài ra nếu dùng đúng cách, nó cũng phần nào xử lý được các vấn đề phức tạp hơn như Lost Update, Phantom Read, Write Skew (tùy theo giải pháp mà mình chọn). Giống với Read Committed, ta cũng chia làm 2 trường phái: sử dụng Lock và không sử dụng Lock.
3.1. Repeatable Read
Phương pháp này có tên gọi trùng với tên của Isolation Level luôn. Nó cải tiến từ cái cách xử lý sử dụng Shared Lock của Read Committed, điểm khác đó là:
- Giải pháp này sẽ lock lại bất cứ row nào mà nó đi qua cho tới khi transaction được kết thúc kể cả là read operation (thay vì ngay khi kết thúc read operation như Read Committed).
- Điều này sẽ dẫn đến xuất hiện trường hợp 1 transaction vừa đọc rồi ghi lại vào row: lock đang được hold sẽ được upgrade từ share mode lên exclusive mode. Quá trình upgrade này cũng phải chờ tất cả các transaction khác release khỏi lock thì mới được diễn ra.
"bất cứ row nào mà nó đi qua" nghĩa rằng Repeatable Read có thể lock bao gồm cả những bản ghi không thuộc kết quả trả về. Nếu bảng của bạn không có index, nhiều khả năng nó sẽ lock luôn toàn bộ bảng.
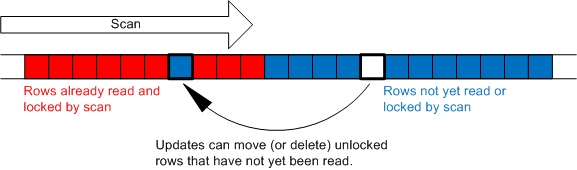
Một điểm cần lưu ý đó là Repeatable Read sử dụng cơ chế lock theo từng object, scan tới đâu thì lock tới đó, chưa scan tới thì vẫn có thể thoải mái bị thread khác write đè lên. Ngoài ra, việc lock cũng bị sót đối với những bản ghi mới được insert vào giữa những row đã scan qua.
Từ đó ta có thể thấy được “sân chơi” của phương pháp này là những transaction chỉ thao tác trên số lượng row hữu hạn biết trước. Ví dụ như get by id, hay delete/update by id, điển hình cho 3 bài toán Read Skew, Lost Update và Write Skew.
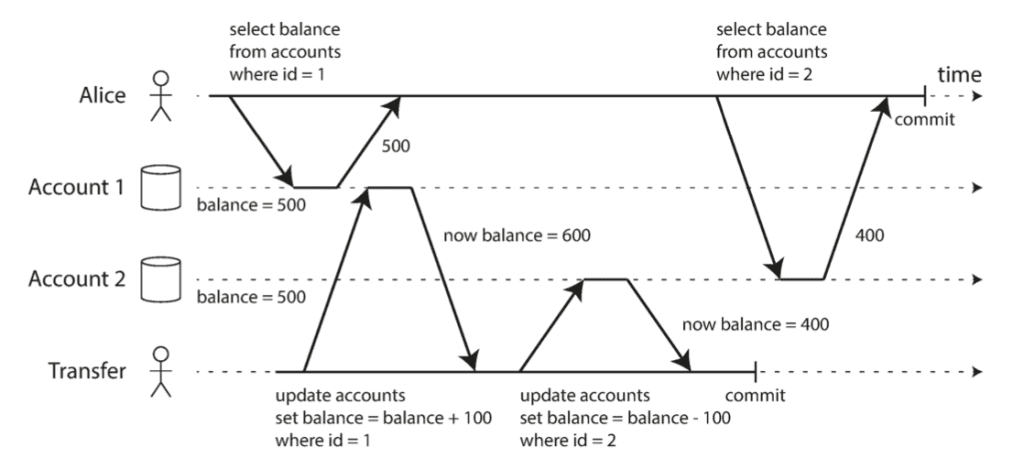
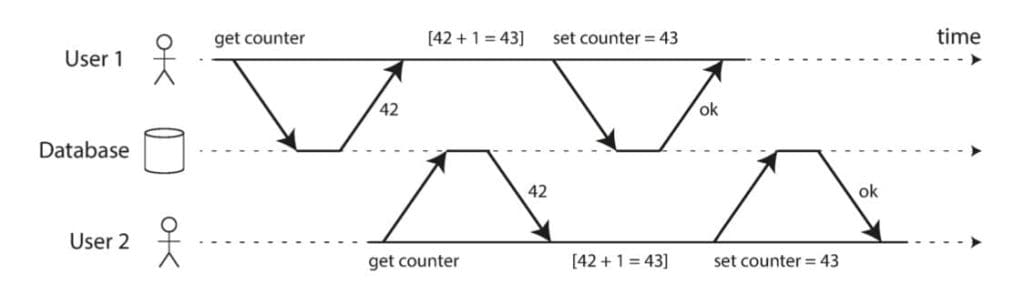
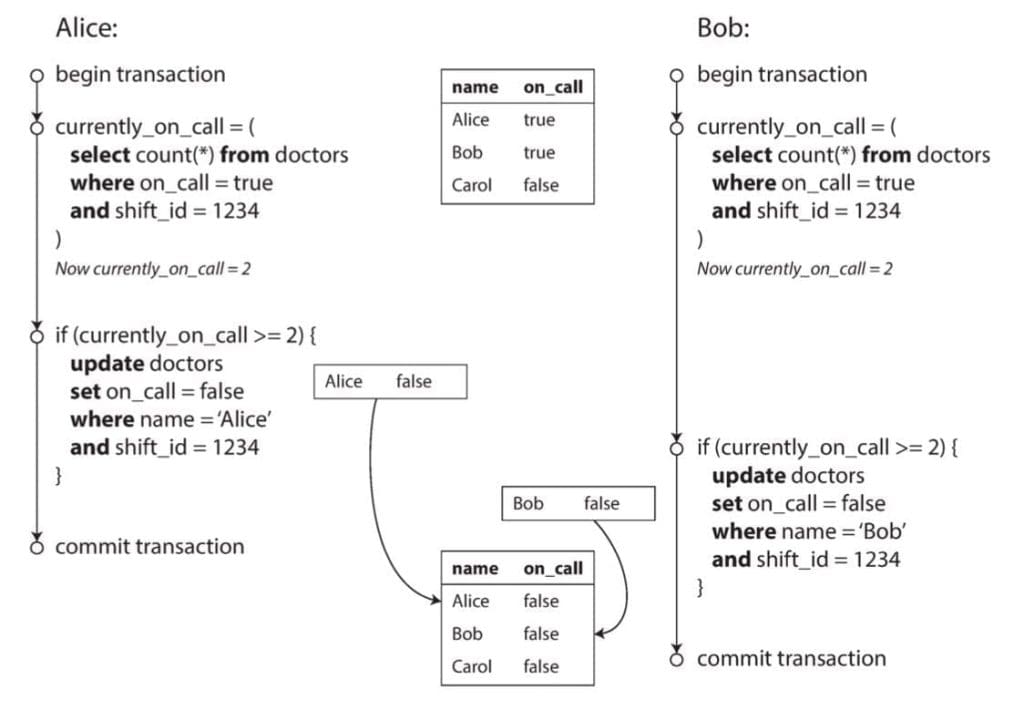
Nhược điểm:
- Không xử lý được với bài toán Phantoms.
- Không lock lại kết quả ngay từ lúc bắt đầu, mà scan tới đâu thì mới lock tới đó.
- Việc sử dụng Lock đối với long-running query có thể khiến các operation khác bị block, gây chậm Database nói chung và tốc độ phản hồi của câu query nói riêng cũng rất chậm.
- Có khả năng bị Deadlock. Ví dụ với ảnh minh họa của bài toán Read Skew: đổi thứ tự giảm account 2 trước thay vì tăng account 1.
3.2. Snapshot Isolation
Phương pháp này cải tiến từ Consistent Read của Read Committed. Trong quá trình query, có rất nhiều row đã được update bởi các transaction khác, thậm chí còn bị update nhiều lần. Thay vì chỉ lưu 2 version, thì ta sẽ lưu toàn bộ các version từ trước tới nay, và chỉ lấy ra version được commit trước khi transaction hiện tại được bắt đầu.
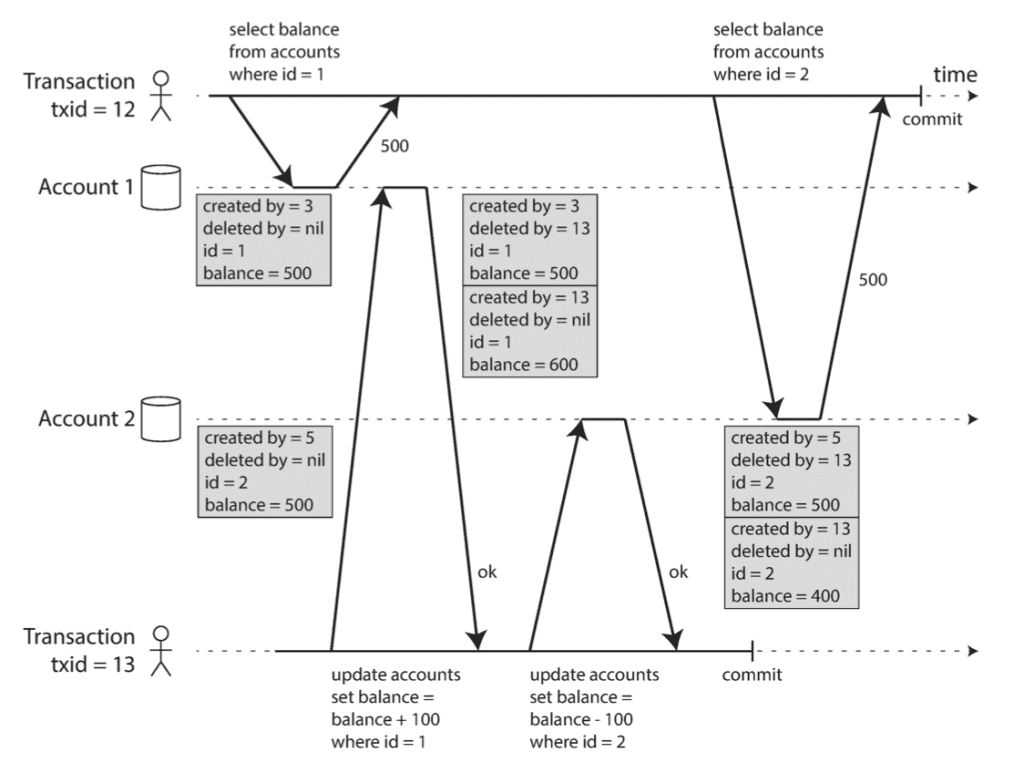
Snapshot Isolation được sinh ra dành cho “sân chơi” read-only transaction, nó khắc phục được hết các nhược điểm của Repeatable Read đối với read-only transaction:
- Kết quả đã được đóng ngay từ lúc bắt đầu transaction, chỉ việc scan và nhặt đúng version là được.
- Xử lý được bài toán Read Skew và Phantom Read.
- Không bị deadlock
- Tốc độ query nhanh
Nhược điểm:
- Không giải quyết được Lost Update, Write Skew và Phantom Write.
- Hơi tốn bộ nhớ.
- Cần phải implement 1 con GC (Garbage Collector) có nhiệm vụ đi xóa bớt những version không còn cần thiết nữa. Ví dụ như TransactionID nhỏ nhất hiện tại đang active là 100, như vậy ta có thể xóa bớt các stale version < 99 đi.
- Không chỉ mỗi row, mà cả các index đi kèm cũng phải đồng thời implement multi-version concurrency control. Khá là lằng nhằng, không hề đơn giản.
4. Serializable
Serializable được định nghĩa là đảm bảo việc thực hiện đồng thời nhiều transaction vẫn sẽ cho ra kết quả giống y hệt với khi ta làm một cách tuần tự.
Đây là mức độ mạnh nhất của Isolation, nhưng sử dụng nó thì sẽ phải trả giá rất lớn cho hiệu suất của chương trình. Cho nên không có Database truyền thống nào cài đặt mức này làm cấu hình mặc định cả. Hiện đang có 3 cách xử lý phổ biến nhất
4.1. Actual Serial Execution
Cách tốt nhất để tránh khỏi các vấn đề về bất đồng bộ đó là hãy xử lý chúng nó lần lượt trên cùng 1 thread. Ý tưởng này nghe có vẻ đơn giản, nhưng thực sự là bắt đầu từ năm 2007 trở lại đây thì nó mới có người quan tâm tới (nhờ vào trào lưu lập trình hướng sự kiện – event loop).
Redis chính là thằng nổi tiếng nhất trong đám này. Ngoài ra còn nhiều Database khác nữa (VoltDB, H-Store, Datomic) cũng sử dụng cách này nhưng chắc ít người biết tới chúng nó. Những Database sử dụng single-thread kiểu này thậm chí còn nhanh hơn cả các Database truyền thống khác, nhờ vào việc không cần sử dụng lock. Vậy lý do nào khiến cho hơn 30 năm trời (từ những năm 1970 cho tới giờ), người ta mới quyết định sử dụng phương pháp này?
- Phần cứng trở nên rẻ hơn và khỏe hơn.
- Lập trình viên bắt đầu nhận thức được việc chia Database dành cho OLTP và OLAP riêng. Đối với những hệ thống OLAP, đa số request là long-running query, nên chỉ cần sử dụng Snapshot Isolation là đủ.
- Nhờ vào sự hỗ trợ của hệ điều hành (Epoll trong Linux)
Nhược điểm của phương pháp này:
- Transaction phải đủ nhỏ và đủ nhanh, để không block các operation khác. Đây là lý do mà hầu hết các Database sử dụng phương pháp này đều lưu data trực tiếp trên memory, thay vì truy cập xuống disk.
- Bị giới hạn trong 1 core CPU. Có thể sử dụng kĩ thuật partitioning để tận dụng nhiều core CPU, tuy nhiên sẽ phải implement lock trong trường hợp cross-partition transaction.
4.2. Two-Phase Locking (2PL)
Chắc tới đây thì anh em cũng bắt đầu tò mò về câu hỏi: hơn 30 năm qua, các Database truyền thống đã dùng phương pháp gì? Câu trả lời chính là Two-Phase Locking.
Hiện nó đang được sử dụng trong MySQL (InnoDB) và SQL Server. Kỹ thuật này cải tiến từ phương pháp Repeatable Read, full nội dung như sau:
- Nếu transaction A đã đọc 1 row và transaction B muốn ghi vào row đó: B phải chờ cho tới khi A kết thúc (commit hoặc abort) thì mới được tiếp tục.
- Nếu transaction A đã ghi vào 1 row và transaction B muốn đọc row đó: B phải chờ cho tới khi A kết thúc (commit hoặc abort) thì mới được tiếp tục.
- Ban đầu khi transaction A muốn đọc 1 row, nó sẽ acquire lock và hold nó cho tới khi kết thúc transaction. Tuy nhiên lock này ở chế độ share mode (tức là nhiều transaction cùng có thể cùng acquire và hold nó).
- Khi transaction B muốn ghi vào row, lock sẽ upgrade lên chế độ exclusive mode. Quá trình upgrade này chỉ được diễn ra khi tất cả các transaction khác đã release khỏi lock đã. Sau đó B sẽ acquire exclusive lock.
- Không transaction nào khác được phép acquire exclusive lock trong lúc vẫn còn transaction chưa release.
- Khi transaction C vừa đọc rồi ghi lại vào row: lock đang được hold sẽ được upgrade từ share mode lên exclusive mode. Tương tự như trên: quá trình upgrade cũng phải chờ tất cả các transaction release khỏi lock.
- Tương tự Repeatable Read, sẽ có trường hợp bị Deadlock. Database cần phải có 1 cơ chế để detect được vấn đề này và abort transaction để retry lại (có thể tự động retry hoặc mình chủ động làm bằng tay).
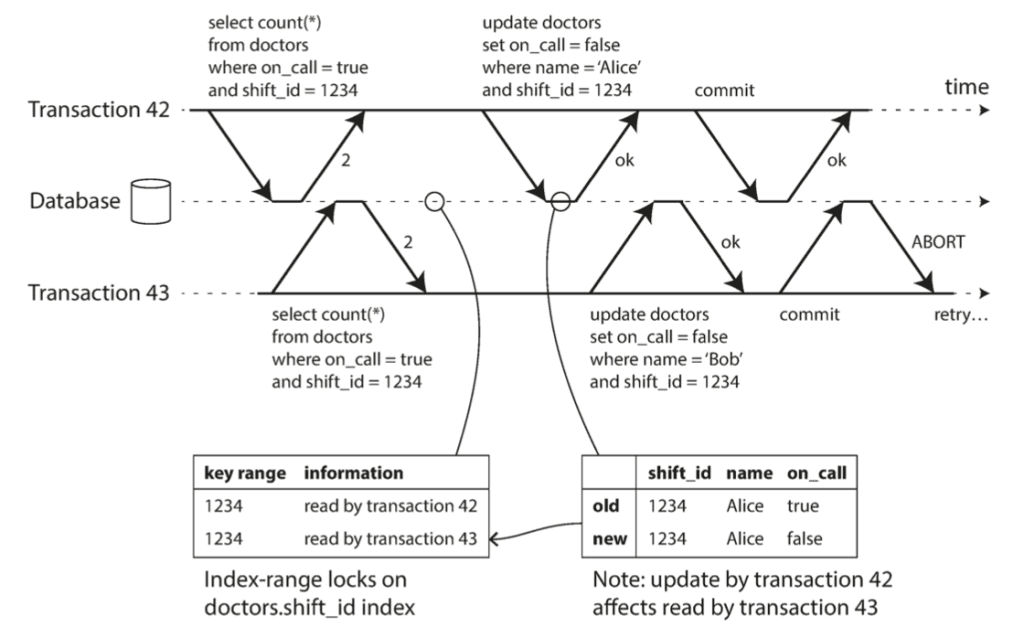
Đấy là lý thuyết, khái quát thì không khác gì Repeatable Read, nhưng thực tế thì Database còn dùng row lock kết hợp với predicate lock hoặc index-range lock nữa.
Row-level lock:
Lock ở mức độ row giống như Repeated Read, không tránh được lỗi Phantoms. Cái này chỉ sử dụng cho những câu query get by id, hay write by id thôi.
Predicate lock:
SELECT * FROM user WHERE age > 10;
- Ngay khi bắt gặp 1 câu lệnh mà không phải thuộc dạng get by id hay write by id, transaction sẽ sử dụng thêm Predicate lock (vẫn dùng cả Row lock, scan tới đâu thì acquire tới Row lock tương ứng ở đó).
- Predicate lock cũng tồn tại 2 chế độ share mode và exclusive mode, nguyên lý tương tự như Row Lock.
- Database sẽ lưu 1 danh sách các Predicate lock đang chưa được release.
- Tất cả các Operation khác (dù chỉ get/write by id) đều phải duyệt qua cái danh sách Predicate lock kia trước khi tới bước acquire Row Lock. Mục đích để check xem row mà transaction định read/write nó có thỏa mãn predicate hay không. Nếu có thì phải tìm cách acquire Predicate lock được release đã thì mới được tiếp tục.
Cách này đã tránh được tình trạng Phantoms, 100% serializable. Tuy nhiên, anh em có thể thấy rằng việc phải check xem row có thỏa mãn predicate hay không rất là tốn thời gian.
Index-range lock:
Để tránh việc phải check row thỏa mãn predicate, mà vẫn muốn lock toàn bộ những row thỏa mãn predicate, ta sử dụng Index-range lock (hay còn gọi là Range lock hoặc Next-key lock).
SELECT * FROM bookings WHERE room_id = 123 AND end_time > '2018-01-01 12:00' AND start_time < '2018-01-01 13:00';
Minh họa cho câu query trên, ta sẽ có 3 sự lựa chọn:
- lock theo index
room_id = 123 - lock theo index
end_time > '2018-01-01 12:00' - lock theo index
start_time < '2018-01-01 13:00'
Ta chỉ cần sử dụng 1 trong 3 thôi, không cần phải lock cả 3 index lại. Như vậy vẫn đảm bảo lock được toàn bộ những row thỏa mãn predicate của câu query (mặc dù lock thừa nhiều bản ghi không cần thiết). Chọn lựa index nào để tối ưu lock thì đó lại là 1 câu chuyện khác, cái đó sẽ do optimizer của Database xử lý.
Tuy nhiên, trong trường hợp tất cả các column trong câu predicate đều không có index, Database sẽ lock trên toàn bộ bảng. Vì vậy, anh em cần kiểm tra xem câu predicate của mình đã có index chưa, trước khi để nó chạy ở mức độ Serializable Isolation.
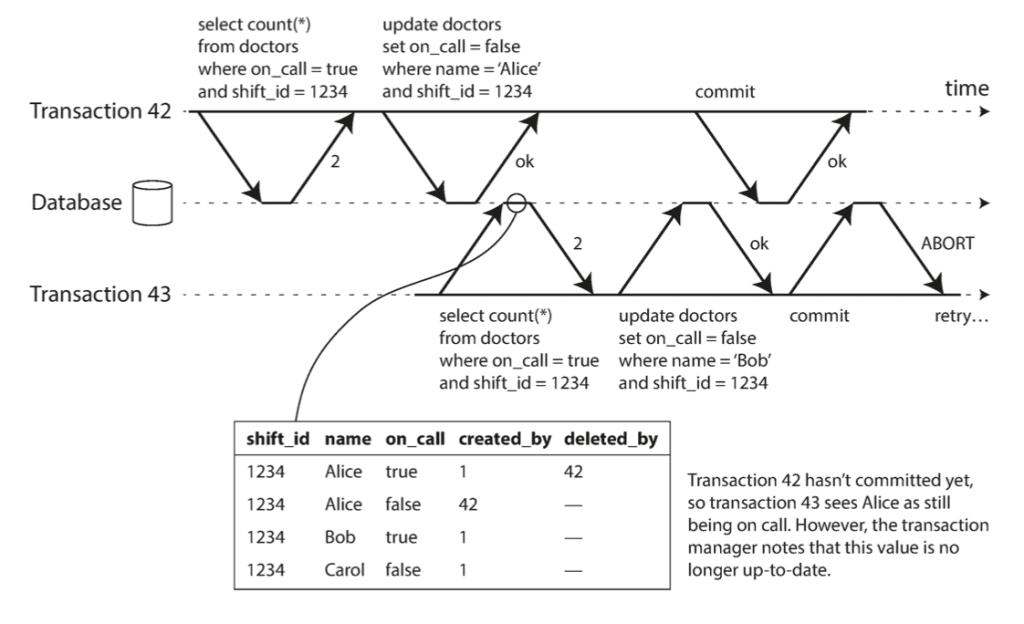
4.3. Serializable Snapshot Isolation (SSI)
Điểm qua lại những thứ ta đã tìm hiểu:
- Snapshot Isolation: cho performance rất tốt, tuy nhiên lại bị gặp phải vấn đề với Lost Update, Write Skew, Phantoms,…
- Actual serial execution: scale kém
- Two-Phase Locking: performance kém
Hầu hết đều được cái này thì mất cái kia, tuy nhiên gần đây đã có nghiên cứu mới về 1 phương pháp có thể dung hòa được tất cả yếu tố bên trên. Thuật toán có tên là Serializable Snapshot Isolation (SSI), được đánh giá rất triển vọng, được ra mắt vào năm 2008 trong luận án tốt nghiệp tiến sĩ của Michael Cahill. SSI hiện đang được sử dụng trong PostgreSQL bắt đầu từ phiên bản 9.1.
Chắc anh em lập trình lâu năm cũng sẽ đâu đó nhìn thấy 2 cái cụm từ Pessimistic và Optimistic Concurrency Control. 2PL và Actual serial execution được coi là Pessimistic, vì nó dựa trên nguyên lý giết nhầm còn hơn bỏ sót (Không cần biết cái operation này có gây vi phạm isolation với transaction khác hay không, cứ lock nó lại cho an toàn).
SELECT COUNT(*) FROM staff WHERE join_time < '2018-01-01 13:00'; UPDATE staff SET revenue = revenue+500 WHERE join_time < '2018-01-01 13:00';
2 câu lệnh bên trên cùng tác động tới những row giống nhau nhưng kết quả thì không ảnh hưởng tới nhau. Loại Optimistic cứ để mọi thứ xảy ra, miễn là nó không ảnh hưởng tới transaction khác; transaction cứ việc thực thi, còn nó có được commit thành công hay không thì đấy lại là một chuyện khác!
Muốn implement được SSI, thì Database cần phải xây dựng thuật toán để phân tích và detect được hành vi vi phạm isolation. Transaction nào vi phạm sẽ bị abort, và cần được retry lại (có thể tự động hoặc mình chủ động retry bằng tay). Chỉ những transaction thỏa mãn tính chất Serializable thì mới được cho phép commit.
Thuật toán SSI khá phức tạp và tuổi đời còn trẻ nên vẫn còn nhiều thứ phải phát triển tiếp, trong phạm vi bài viết này tôi xin phép không đề cập chi tiết. Về cơ bản, nó được implement dựa trên ý tưởng của phương pháp Snapshot Isolation. Vì thế nên nó mới có cái tên là Serializable Snapshot Isolation.
Leave a Reply