
SSTable là gì?
Trước khi tiếp tục cái series về Database, ta sẽ tìm hiểu qua trước về Sorted String Table, hay còn được gọi là SSTable. Về bản chất thì nó khá giống với kiến trúc Log file được đề cập từ 2 phần trước:
Điểm khác biệt duy nhất đó là: mỗi key trong SSTable đều chỉ xuất hiện 1 lần duy nhất (không có chuyện trùng lặp Key), và các row được sắp xếp theo Key.
SSTable có nhiều ưu điểm lớn so với việc sử dụng Hash Index:
- Việc merge segment SSTable là đơn giản và hiệu quả hơn. Cách triển khai của nó khá giống với thuật toán MergeSort: Ta bắt đầu bằng việc đồng thời quét bản ghi đầu tiên của từng Segment. Sau đó chọn ra Key nhỏ nhất để ghi vào Merged Segment (trong trường hợp có Key cùng có mặt trên nhiều Segment, ta chọn bản ghi gần nhất và bỏ qua giá trị trên các Segment cũ hơn).
Nếu bản ghi hiện tại có Key trùng với giá trị được ghi vào Merged Segment, ta quét sang bản ghi kế tiếp, và lặp lại bước bên trên.

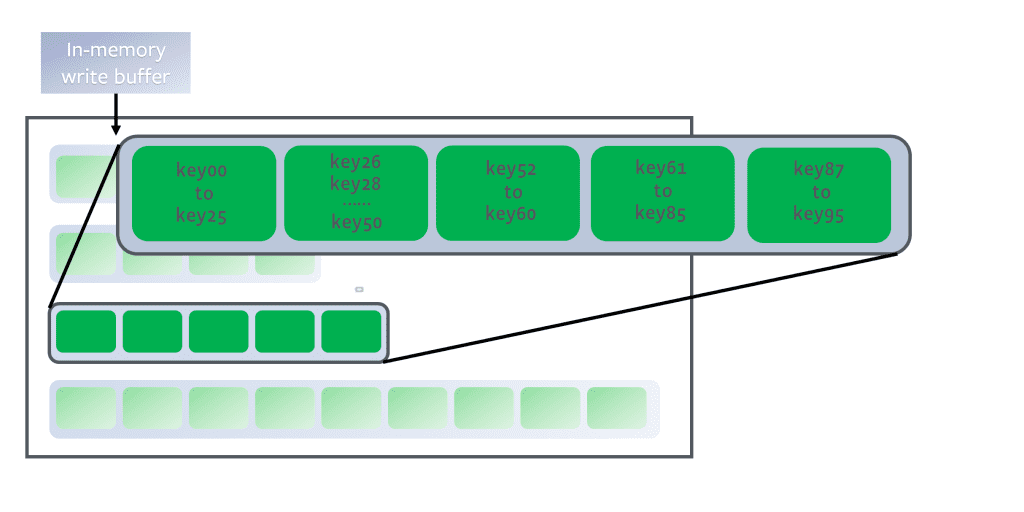
- Để tìm 1 giá trị Key nào đó trong SSTable, ta không cần phải đánh index cho toàn bộ Key vào bộ nhớ nữa. Xem hình minh họa bên dưới để dễ hình dung: giả thiết rằng bạn đang cần tìm key
handiwork, bạn không biết chính xác offset của nó là gì. Tuy nhiên, bạn lại biết rằng offset của keyhandbagvàhandsome, nhờ vào tính chất thứ tự được sắp xếp của SSTable nênhandiworksẽ nằm giữa 2 key kia.
Như vậy: ta sẽ seek tới offset của keyhandbag, và scan cho tới khi tìm thấy keyhandiworkhoặchandsome. Nếu không thấyhandiwork, tức là nó không tồn tại trong SSTable.

Như vậy, ta vẫn cần in-memory index để chỉ dẫn offset tới key của SSTable, nhưng nó sẽ thưa hơn so với Hash Indexes vì chỉ cần lưu offset 1 vài key đại diện cho từng block. Mỗi block chứa đâu đó vài KB là ok, đủ để scan bên trong nó không quá tốn kém. Kiến trúc Index này còn có tên gọi là LSM-Tree Index.
- Nén từng block thay vì nén cả file: bên cạnh việc tiết kiệm được kha khá kích thước của file SSTable, thì điều này cũng giúp giảm được kha khá băng thông disk I/O.
Khởi tạo và duy trì SSTable bằng cách nào?
Quay trở lại với thiết kế Log-Structured Engine, ta sẽ áp dụng SSTable như nào?
Việc duy trì cấu trúc dữ liệu có thứ tự ở trên Disk là hoàn toàn có thể làm được (ví dụ như BTree Index ta sẽ tìm hiểu ở bài sau). Tuy nhiên, thực hiện điều đó ở trên memory sẽ đơn giản hơn nhiều: có thể dùng Red-Black Tree hoặc AVL Tree. 2 loại cấu trúc dữ liệu dạng cây nhị phân này đều cho phép insert key rồi đọc ra theo thứ tự đã được sắp xếp, tùy vào mục đích sử dụng thì ta sẽ xem xét sử dụng cái nào:
- AVL có độ cân bằng tối ưu hơn so với RBTree, chính vì thế, chi phí để duy trì độ cân bằng này lớn hơn.
- AVL truy vấn nhanh hơn, nhưng insert, delete chậm hơn. Bạn read nhiều hãy chọn AVL Tree, bạn insert, delete nhiều, hãy chọn Red-Black Tree.
- Red-Black Tree được Java chọn để implement TreeMap.
Luồng xử lý của chúng ta sẽ thay đổi thành như sau:
- Khi có request ghi mới, ta cập nhật nó vào trong 1 cây nhị phân in-memory (thường là Red-Black Tree), còn được gọi là memtable.
- Khi memtable trở nên lớn hơn ngưỡng kích thước cho trước, ta sẽ lưu nó xuống Disk dưới định dạng SSTable và tạo LSM-Tree Index đi kèm. Việc này có thể thực hiện dễ dàng, vì cây nhị phân vốn đã hỗ trợ cho việc duyệt từ giá trị nhỏ nhất tới lớn nhất rồi. SSTable mới được tạo sẽ trở thành segment gần đây nhất của DB, trong lúc đó thì chương trình sẽ tiếp tục ghi ra 1 memtable mới.
- Để tìm kiếm 1 Key trong DB, đầu tiên ta tìm trong memtable hiện tại, nếu không thấy thì tìm tới segment gần đây nhất, cho tới các segment cũ hơn.
- Định kỳ theo thời gian, chạy 1 tiến trình compaction để gom các file segment và lọc bỏ đi các giá trị đã bị xóa/ghi đè.
Yếu điểm duy nhất của cách làm trên đó là: nếu DB bị crash, những giá trị gần nhất nằm trong memtable sẽ bị mất. Để giải quyết vấn đề đó, ta ghi vào append-only log trên disk, giống như bài trước. Mỗi memtable sẽ có file log riêng, nó được lưu theo thứ tự insert, thay vì được sắp xếp theo key, nhưng không sao cả, vì nó chỉ dùng cho mục đích khôi phục DB mà thôi. Ngay khi memtable được ghi xuống SSTable, ta có thể xóa file log cũ đi.
Ứng dụng thực tế:
Kiến trúc LSM-Tree Index này lần đầu được công bố bởi Patrick O’Neil và cộng sự vào năm 1996 dưới cái tên Log-Structured Merge-Tree. Những storage engine dựa trên nguyên lý của LSM-Tree thường được gọi là LSM Storage Engine, có thể kể đến những cái tên rất quen thuộc sau đây:
- RocksDB, LevelDB: 2 thư viện key-value storage rất nổi tiếng thường được dùng làm embedded DB bên trong các chương trình. LevelDB còn được dùng trong Riak như 1 sự thay thế cho Bitcask (vốn bị giới hạn bởi RAM).
- Cassandra, HBase: cả 2 con hàng này đều được lấy cảm hứng từ paper BigTable của Google (trong đó có đề xuất tới 2 khái niệm memtable và SSTable).
- Lucene: được sử dụng bởi Elasticsearch và Solr, đang dùng kiến trúc tương tự với LSM-Tree. Full-text index phức tạp hơn key-value index rất nhiều, tuy nhiên cũng dựa trên ý tưởng giống nhau: dựa vào những từ trong câu truy vấn search, tìm tất cả các document có đề cập tới từ đó -> key là 1 từ (hoặc 1 cụm từ), và giá trị là danh sách ID của tất cả các document có chứa nó.
Tối ưu hiệu suất
Như thường lệ, có rất nhiều chi tiết lặt vặt cần được giải quyết khi chạy trong thực tế:
- Thuật toán LSM-Tree sẽ bị chậm nếu như truy vấn Key không tồn tại trong DB: ta sẽ phải tìm trong memtable rồi tìm lần lượt trong từng SSTable từ mới nhất tới cũ nhất (phải scan dưới disk). Để tối ưu cho trường hợp này, ta có thể sử dụng thêm cấu trúc dữ liệu Bloom Filter (mình có từng đề cập ở đây, mọi người có thể vào đọc tham khảo).
- Có nhiều kiểu chiến thuật khác nhau để quyết định thứ tự và thời điểm mà các SSTable sẽ được compact và merge. Có 2 lựa chọn phổ biến nhất là size-tiered compaction và leveled compaction:
- LevelDB và RocksDB sử dụng leveled compaction (đúng như cái tên gọi của LevelDB)
- HBase sử dụng size-tiered, và Cassandra thì hỗ trợ cả 2.
Chiến lược size-tiered:
Tiến trình compaction sẽ được kích hoạt khi mà có đủ n SSTable kích thước tương đương nhau.
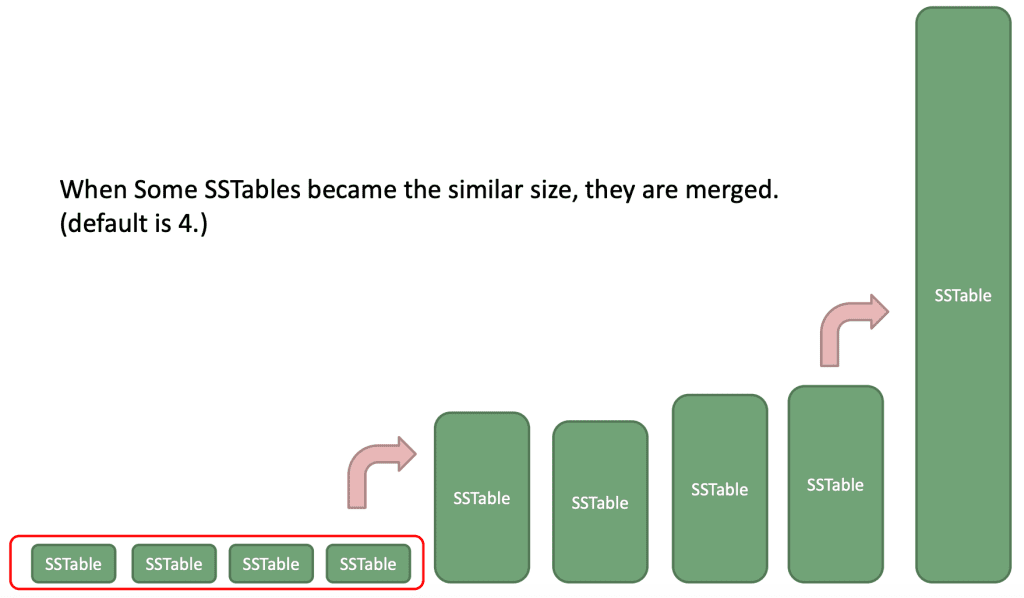
Nhược điểm của nó là kích thước dữ liệu trong disk lớn (cho tới khi được compact), và key sẽ nằm rải rác trong nhiều SSTable nếu ta liên tục sửa giá trị của nó (không thích hợp cho việc scan key range vì mỗi phần của kết quả truy vấn lại nằm ở các SSTable khác nhau).
Chiến lược leveled compaction:
Chia thành nhiều level, bắt đầu từ L0 (SSTable gần đây sẽ nằm ở level thấp, càng lên cao thì càng cũ). Trong cùng level thì mỗi SSTable sẽ đảm nhiệm lưu trữ dải Key nhất định, không trùng (overlap) với SSTable khác. Điều này giúp cho kích thước dữ liệu trong disk nhỏ, và truy vấn trở nên nhanh hơn vì không phải quét quá nhiều SSTable. Nếu có L tầng thì trường hợp xấu nhất chỉ phải quét L SSTable, thực tế 90% là chỉ phải quét 1 SSTable.
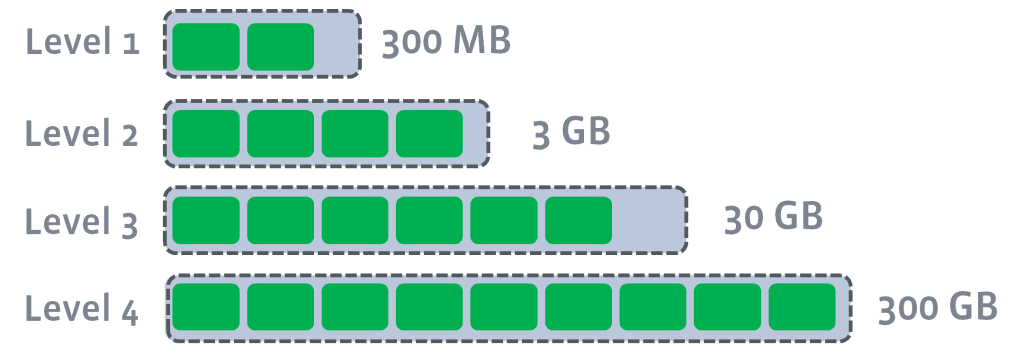
Ta có thể compact song song nhiều segment cùng 1 lúc (miễn là chúng không overlap lẫn nhau). Tuy nhiên tầng L0->L1 không thể compact song song được, ngoài ra nó sử dụng nhiều Disk I/O hơn và thời gian cho 1 lần compact cũng lâu hơn so với Size-tiered Compaction.
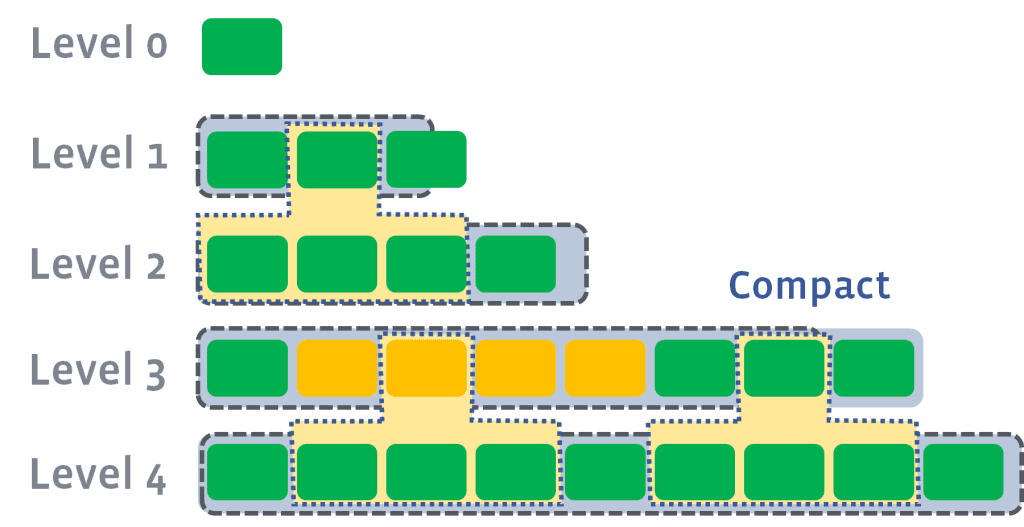
Khi sử dụng Leveled Compaction, ta phải cẩn thận với những ứng dụng write nhiều, DB sẽ không compact kịp. Chi tiết hơn thì mọi người có thể xem thêm ở đây.
Ưu điểm:
Thuật toán LSM-Tree đã giải quyết được hết những nhược điểm lớn của Hash Index, hiện nó đang là thuật toán phổ biến nhất trong các DB sử dụng Log-Structured Engine (đa phần là các DB NoSQL). Nó vẫn chạy trơn tru kể cả khi dữ liệu trong DB đã vượt quá rất nhiều so với kích thước của bộ nhớ. Vì dữ liệu được lưu trữ 1 cách có thứ tự, ta có thể thực hiện những câu truy vấn range (bản chất là scan trong 1 khoảng key). Dữ liệu được ghi 1 cách tuần tự xuống disk nên Log-Structured nói chung và LSM-Tree nói riêng có thể đáp ứng được nhu cầu ghi cực lớn.

Leave a Reply