Ta sẽ tiếp tục cải tiến từ cấu trúc log file của bài trước (Database 101: Log Structured Storage). Ý tưởng lần này bắt nguồn từ sự tương đồng giữa Key-Value Store và cấu trúc dữ liệu HashMap (Hash Table) – thường đã có sẵn trong hầu hết các ngôn ngữ lập trình hiện nay. Ta sẽ tận dụng HashMap để lưu index cho dữ liệu trên disk vào trong RAM.
Nhớ lại từ phần trước, dữ liệu ở trong disk được lưu nối tiếp nhau trong 1 file, và được ngăn cách nhau bởi ký tự xuống dòng. Hạn chế của việc này đó là khi truy vấn, ta sẽ phải quét toàn bộ file từ đầu tới cuối, rồi chọn ra line cuối cùng trong các kết quả tìm được.
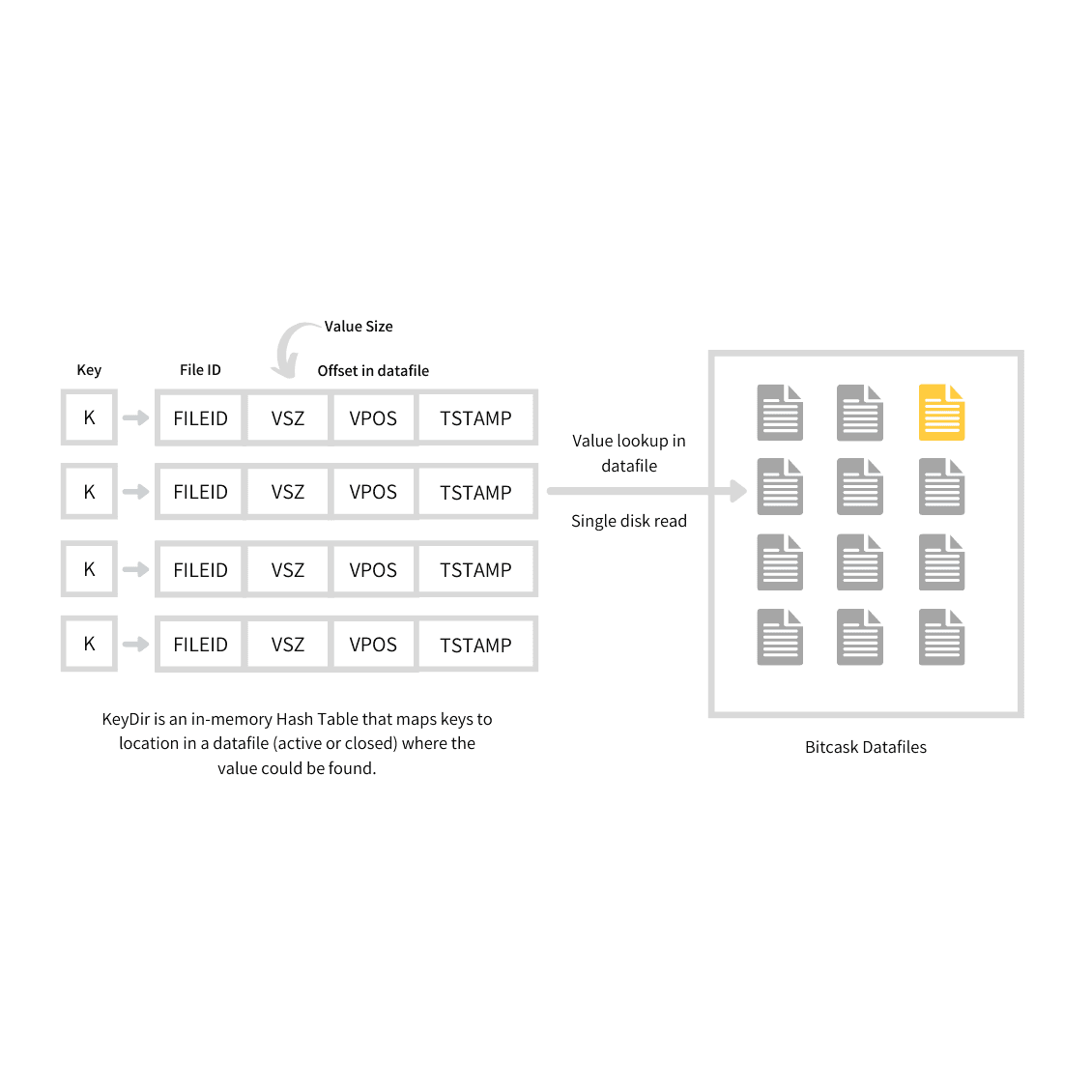
Giải pháp đơn giản cho vấn đề này đó là: lưu 1 HashMap ở trong RAM, trong đó mỗi key sẽ ánh xạ tới offset trong file log – nơi mà giá trị đang được lưu trữ (minh họa như trong hình bên dưới). Khi bạn lưu 1 cặp key-value mới vào DB, đồng thời hãy update vào HashMap giá trị của offset mà bạn vừa mới ghi (cách này dùng được cho cả trường hợp insert và update). Còn khi bạn truy vấn, sử dụng HashMap để lấy ra offset tương ứng, thực hiện seek file tới vị trí đó và đọc giá trị.
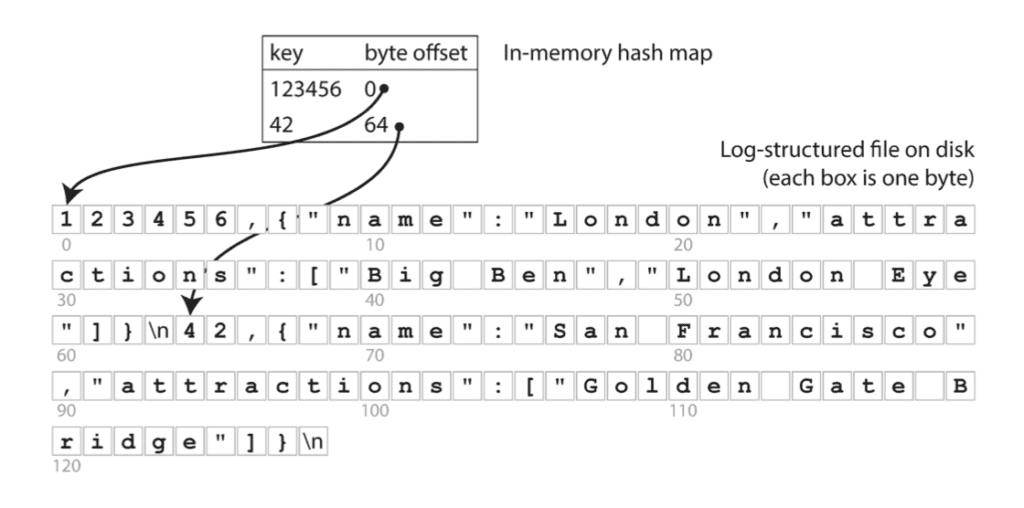
Cách này vô cùng đơn giản, nhưng cũng là 1 hướng tiếp cận khả thi. Thực tế, đây chính là cách mà Bitcask (storage engine mặc định của Riak) đang làm. Bitcask cho phép đọc-ghi với hiệu suất cao, điểm trừ đó là index bị giới hạn bởi dung lượng RAM. Dữ liệu trong DB được load trực tiếp từ disk thông qua việc seek file nên không bị ảnh hưởng bởi kích thước bộ nhớ. Chưa kể, filesystem cũng có cơ chế cache, nên nhiều khi ta còn chẳng cần phải đụng tới thao tác disk IO để đọc dữ liệu.
Storage engine như Bitcask phù hợp với những bài toán mà giá trị được cập nhật liên tục. Chẳng hạn, Key là URL của 1 video, và Value là số lượng lượt xem (tăng dần mỗi khi có người nhấn vào play video). Tổng quát hơn thì Hash Index phù hợp với bài toán mà có rất nhiều lượt ghi vào DB, tuy nhiên số lượng Key là không nhiều (đủ để chứa được trong bộ nhớ).
Nếu ta tính xa hơn, sẽ nhận ra rằng DB của mình chỉ toàn append vào file log mà không có xóa bớt đi, vậy cuối cùng rồi nó sẽ bị đầy dung lượng disk mất sao? 1 phương án rất hay đó là dừng việc ghi file log hiện tại khi nó đã đạt tới 1 ngưỡng kích thước nhất định, và tiếp tục ghi sang 1 file log mới. Sẽ có 1 tiến trình ngầm gọi là compaction, chuyên định kỳ quét các phần log (segment) cũ, loại bỏ các giá trị Key trùng lặp và giữ lại giá trị gần nhất.
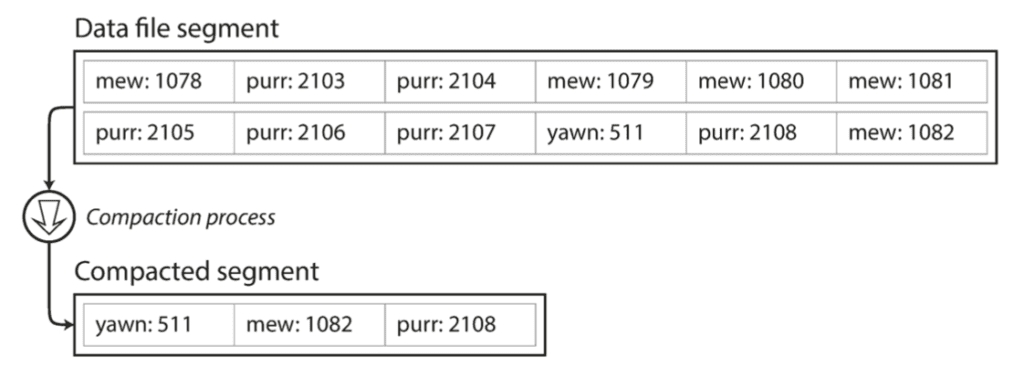
Segment không bị sửa đổi trong quá trình compact, nó vẫn được sử dụng để phục vụ cho việc truy vấn của DB. Kết quả của quá trình compact sẽ được ghi ra 1 file mới (merged segment). Tới khi hoàn thành, DB chuyển hướng read request từ đọc segment cũ sang đọc merged segment, lúc này ta có thể xóa các segment đã được compact kia đi. Quá trình compact có thể xử lý cùng lúc 1 hoặc nhiều segment, như hình bên dưới:
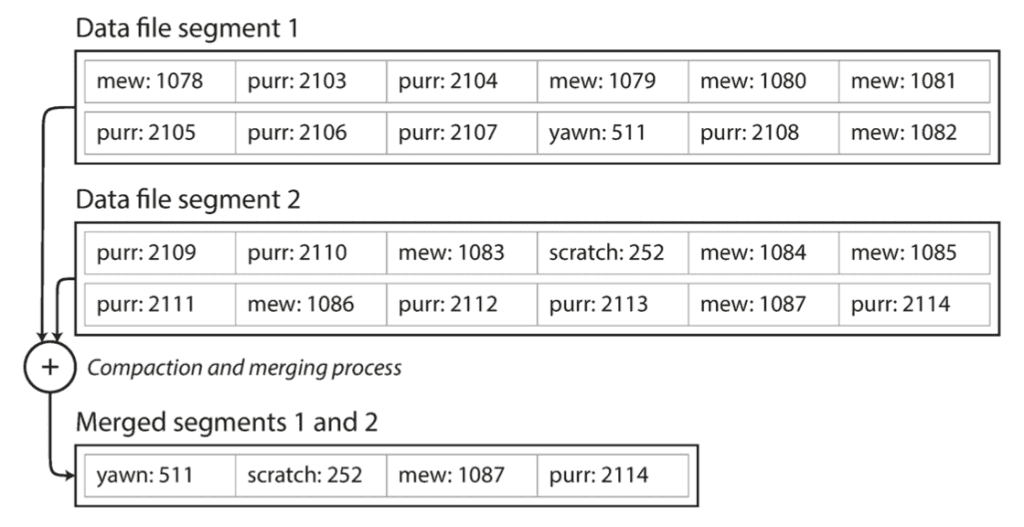
Chú ý: mỗi segment có 1 HashMap của riêng nó, ánh xạ từ key tới offset của segment. Để tìm giá trị của Key trong DB, ta kiểm tra lần lượt từ HashMap của segment gần đây trước: nếu Key không tồn tại trong HashMap, ta tiếp tục kiểm tra tới segment cũ hơn tiếp theo,… Vì quá trình compaction sẽ luôn cố giữ số lượng segment ít nhất có thể, nên yên tâm rằng DB sẽ không cần phải kiểm tra quá nhiều HashMap.
Phía trên là ý tưởng cơ bản của Hash Index, trong thực tế để có thể chạy được thì ta còn phải chau chuốt rất nhiều chi tiết nhỏ nhặt khác, dưới đây sẽ liệt kê 1 số vấn đề đáng chú ý:
- File format: CSV không phải là format tốt dành cho log. Nó sẽ nhanh hơn và đơn giản hơn nếu dữ liệu được lưu dưới dạng binary, trong đó những byte đầu dùng để lưu kích thước của data được ghi, phía sau là giá trị String được encode dưới dạng mảng byte (không cần escape ký tự như CSV).
- Xóa: Nếu bạn cần xóa 1 Key, ta append vào file log 1 giá trị đặc biệt được quy ước để đánh dấu xóa.
- Crash Recovery: Trong trường hợp DB bị restart, HashMap trong bộ nhớ sẽ bị mất. Về lý thuyết, bạn hoàn toàn có thể khôi phục lại HashMap của mỗi segment dựa vào việc quét lại từ đầu tới cuối file log segment. Tuy nhiên, việc này có thể gây tốn rất nhiều thời gian nếu kích thước của segment lớn. Bitcask giải quyết vấn đề này bằng cách lưu snapshot của HashMap vào disk, ta có thể load nó lại vào bộ nhớ 1 cách nhanh chóng.
- Partially written record: Đây là tình trạng mà đang ghi giữa chừng thì bỗng dưng DB bị crash. Bitcask sử dụng cơ chế checksum để phát hiện các phần bị hư hỏng, và bỏ qua.
- Kiểm soát đồng bộ (concurrency control): Cách tiếp cận thông dụng nhất đó là chỉ sử dụng 1 luồng (thread) cho việc ghi. Trong khi đó, vì data là append-only và immutable (bất biến) nên ta có thể dùng nhiều thread cho việc đọc.
Tại sao không ghi đè lên giá trị cũ?
Việc sử dụng append-only log (AOL) nhìn qua có vẻ lãng phí, ta đã có offset của Key, vậy tại sao không ghi đè Value mới lên vị trí cũ trên Disk. Thực ra thiết kế append-only log hóa ra lại rất tốt vì những lý do sau đây:
- Việc ghi append và compaction là các thao tác ghi tuần tự, nên nó nhanh hơn và tốn ít disk I/O hơn việc ghi ngẫu nhiên, đặc biệt là trên ổ đĩa cứng từ tính thông thường (trong đó có HDD). Lý do liên quan tới việc con trỏ phải quét từ vị trí ngẫu nhiên này sang vị trí ngẫu nhiên khác sẽ tốn kém thời gian hơn là chỉ cần nhích sang ô bên cạnh (Đọc sâu hơn thì xem link này: https://stackoverflow.com/a/61753068/4728650). Việc ghi ngẫu nhiên trên ổ đĩa SSD sẽ nhanh hơn nhiều, tuy nhiên ghi tuần tự vẫn được ưa thích hơn (lý do liên quan tới thuật toán garbage collector của ổ đĩa).
- Việc quản lý đồng bộ và crash recovery đối với append-only log là đơn giản hơn rất nhiều. Ta sẽ không cần phải quan tâm tới việc đang ghi đè lên giá trị cũ giữa chừng thì bị crash, dẫn tới “mất cả chì lẫn chài” (dữ liệu mới và cũ lẫn lộn lên nhau, không thể dịch ra được).
- Tránh được vấn đề phân mảnh dữ liệu theo thời gian.
Nhược điểm của Hash Index
- Kích thước HashMap không được lớn hơn kích thước bộ nhớ, nên nó không phù hợp với bài toán cần lưu trữ rất nhiều Key.
- Không hỗ trợ range query: Ví dụ, bạn không thể scan những bản ghi có key trong đoạn
kitty00000–kitty99999, thay vào đó phải duyệt (foreach) lần lượt từng key và tìm kiếm trong HashMap.
Ở phần tiếp theo, ta sẽ tìm hiểu tiếp về 1 loại Index khác có khả năng khắc phục được những nhược điểm trên:

Leave a Reply