Bloom filter là 1 cấu trúc dữ liệu xác suất dùng để kiểm tra xem 1 phần tử có thuộc 1 tập dữ liệu hay không?
Sở dĩ lý do lại là cấu trúc dữ liệu xác suất, bởi vì kết quả trả về của Bloom filter không đảm bảo chắc chắn rằng phần tử đó thuộc tập dữ liệu, vẫn sẽ có sai số nhất định.
Cho tập S gồm N phần tử, kiểm tra 𝑥 có là phần tử của tập S (x\in S) hay không.
Bài toán trên rất đơn giản và có nhiều cách để giải:
- Cách đơn giản nhất đó là duyệt qua từng phần tử trong tập -> Cách làm này có độ phức tạp về thời gian là O(N)
- Cách khác đó là lưu tập S trong RAM, sử dụng cấu trúc dữ liệu Hash Table (hay còn gọi là HashMap/HashSet) -> Thời gian là hằng số, gần như trực truy (Random Access).
Tuy nhiên nếu như tập S là lớn (cho đến cực lớn) thì sao? Hoặc nói chung hơn, chi phí để duyệt được S là tốn kém, cũng như việc liên tục truy xuất xuống ổ đĩa khiến cho chi phí kiểm tra cũng là không hề nhỏ.
Và đó là hoàn cảnh dẫn đến việc Bloom Filter được ưa chuộng, mặc dù nó được đánh giá khá là “dumb“. Bloom Filter có tư tưởng phần nào đó giống với HashTable nhưng lại tối ưu về không gian hơn, nhanh chóng phát huy được tính ứng dụng của mình thông qua việc giảm truy vấn tới những tài nguyên expensive-to-access (như database, disk, network,…).
Ứng dụng của Bloom Filters rất rộng, sau đây là một vài ví dụ:
- Google BigTable, Apache HBase, Apache Cassandra, RocksDb (nói chung là rất nhiều DB NoSQL khác nhau) và PostgreSQL sử dụng Bloom Filter để giảm chi phí tìm kiếm dữ liệu.
- Google Chrome ứng dụng để lọc ra và cảnh báo những trang web gây hại cho người dùng.
- Medium dùng để tránh gợi ý lại những bài viết mà user đã đọc.
- Chống DDoS hệ thống.
- Kiểm tra weak password hoặc username/email đã tồn tại trong hệ thống.
- Kiểm tra chính tả bằng cách kiểm tra các từ tồn tại trong từ điển.
Nguyên lý hoạt động của Bloom Filter
Ta sử dụng mảng bit gồm M phần tử 0, gọi nó là BF (để phân biệt với tập S của bài toán)

Khi 1 phần tử mới được thêm vào tập S, ta sẽ hash nó lại và đánh dấu bit ở vị trí tương ứng thành 1:
func Add(x):
position = hash_function(x) % M
BF[position] = 1Thông thường trong thực tế ta sử dụng nhiều hàm hash cùng 1 lúc, số lượng hàm hash sử dụng ta gọi là tham số k. Các hàm hash function sử dụng trong bloom filter nên là những hàm hash có tính độc lập và kết quả là một tập hợp được phân bố một cách đồng đều. Các hàm hash này cũng nên có thời gian xử lý nhanh và tốn ít tài nguyên (vì lí do này các hàm hash mang tính mật mã như sha1 thường ít được sử dụng). Các hàm hash thường được sử dụng có thể kể đến murmur, fnv,…
Có 1 vấn đề đặt ra là giả sử ta có 1 bloom filter cần tới k hàm hash (các hàm hash phải khác nhau), vậy chẳng lẽ ta phải tìm k thuật toán hash khác nhau cho bloom filter này? Giải pháp cho vấn đề này là thuật toán Double Hashing. Chỉ với 2 hàm hash độc lập, sử dụng double hashing ta có thể tạo ra một hàm hash hoàn toàn mới:
func Add(x):
a = hash_function1(x)
b = hash_function2(x)
for i in range(k):
position = (a + i * b) % M
BF[position] = 1
Khi thêm phần tử mới khác, ta tiếp tục thao tác lại như trên, bit được set có thể đang là bit 0 hoặc đã được đánh dấu 1 sẵn từ trước (điều đó không quan trọng). Dần dần sau N phần tử được add, mảng BF của chúng ta nó sẽ trông như này:

Để kiểm tra giá trị x có thuộc tập S hay không, ta thực hiện hash nó và kiểm tra bit tương ứng:
func Check(value):
a = hash_function1(x)
b = hash_function2(x)
for i in range(k):
position = (a + i * b) % M
if BF[position] == 0:
return False
return (y in S)Dễ thấy rằng:
- Trong trường hợp có ít nhất 1 giá trị hash mà tại đó bit = 0, vậy tức là x không thuộc tập S (chắc chắn 100%).
- Nếu tất cả đều thỏa mãn bit = 1 -> x có thể thuộc S, tuy nhiên vẫn cần kiểm tra tiếp để chắc chắn (nếu thực sự x không nằm trong S thì đây chính là trường hợp rơi vào xác suất dương tính giả — false positive).
- Độ phức tạp của thuật toán là O(k), tức là hằng số không phụ thuộc vào N.
Nhắc lại 1 chút:
- True Positive: Nếu x\in BF và x\in S -> Bloom Filter cho kết quả True Positive.
- False Positive: Nếu x\in BF và x\notin S -> Bloom Filter cho kết quả False Positive.
- True Negative: Nếu x\notin BF và x\notin S -> Bloom Filter cho kết quả True Negative.
- False Negative: Nếu x\notin BF và x\in S -> Bloom Filter cho kết quả False Negative.
Trông cái Bloom Filter này khá là dumb, vậy mà tỉ lệ False Positive của nó thấp tới không ngờ á. Dưới đây là biểu đồ minh họa về tỉ lệ False Positive (đại khái là M và k càng lớn thì tỉ lệ này càng nhỏ)

Xác suất False Positive của Bloom Filter
Trước khi bắt đầu mục này, mình paste trước luôn cho các bạn kết quả nó ra là: \left (1-e^{-kN/M} \right )^{k}. Các bạn có thể lắp số lượng N mà ứng dụng của chính mình sẽ expect sử dụng, và thay thử các cặp M và k khác nhau để ước lượng xác suất False Positive sẽ gặp phải.
Ai không quan tâm lắm tới toán học thì có thể next qua mục này, còn ai mà ngạc nhiên (vì False Positive quá nhỏ) và tò mò giống mình thì hẵng đọc. Cũng dễ hiểu thôi, không khó quá như mình tưởng.
Ta bắt đầu minh họa với M=15 và k=3 sau lần insert đầu tiên:


Chia mảng BF thành 3 đoạn bằng nhau (dài 5 bit), với tính chất của hàm hash thì số lượng bit kì vọng được set = 1 trong mỗi đoạn sẽ là 1.
Như vậy, xác suất để 1 bit bất kỳ trong mỗi đoạn được set = 1 là: 1/5
-> Tổng quát hóa: Xác suất để 1 bit bất kỳ trong mỗi đoạn được set = 1 là: \frac{1}{m} (với m=\frac{M}{k})
-> Xác suất để 1 bit vẫn giữ nguyên giá trị trong mỗi đoạn là:
1-\frac{1}{m}-> Như vậy sau khi N phần tử được insert vào thì xác suất để 1 bit bất kỳ trong đoạn vẫn chưa được set = 1 là:
\left ( 1-\frac{1}{m} \right )^{N}-> Ngược lại, xác suất để 1 bit bất kỳ trong đoạn đã từng được set = 1 là:
\rho =1-\left ( 1-\frac{1}{m} \right )^{N}\approx1-e^{-N/m}Trong biểu thức trên, mình đã sử dụng khai triển Taylor để biến đổi xấp xỉ 1-\frac{1}{m} \approx e^{-N/m}.
-> Với m đủ lớn, xác suất xảy ra False Positive tương đương với:
P=\rho ^{k}=\left (1-e^{-N/m} \right )^{k}=\left (1-e^{-kN/M} \right )^{k}Dựa vào P ta hoàn toàn có thể truy ngược lại N (ngưỡng số lượng phần tử, tại đó Bloom Filter rơi vào tình trạng cảnh báo, rất dễ xảy ra False Positive)
N\approx M\frac{\ln \rho \ln \left ( 1-\rho \right )}{-\ln P}Cố định M và P, giải cái bất đẳng thức ở vế bên phải thì ta thu được giá trị lớn nhất của N:
N\approx M\frac{\left (\ln 2 \right )^{2}}{\left |ln P \right |}Giá trị lớn nhất đạt được khi p=1/2, thay vào công thức P=\rho ^{k}, ta được:
k=\log_{2}\left ( \frac{1}{P} \right )Ta thử allocate khoảng 32kB~262144 bit và xem kết quả xác suất False Positive (đừng ngạc nhiên nha, chỉ cần 32kB thôi đó)
| P | 0.1% | 0.01% | 0.001% | 0.0001% |
| k | 10 | 14 | 17 | 20 |
| m=M/k | 26214 | 18724 | 15420 | 13107 |
| N | 18232 | 13674 | 10939 | 9116 |
Một số lưu ý đi kèm:
- Bloom Filter truyền thống không hỗ trợ thao tác xoá, nhưng có nhiều biến thể của nó giải quyết được vấn đề này (Counting bloom filter, Cuckoo Filter, …).
- Bloom filter không lưu trữ phần tử như các CTDL thông thường, nó chỉ kiểm tra khả năng tồn tại của phần tử, vậy nên vẫn cần một bước truy vấn thật sự để lấy ra phần tử mong muốn (và vì thế nó được gọi là filter).
- Xử lý ra sao khi mà kích thước tập S đã tới ngưỡng cảnh báo N? Có 1 phương pháp đó là allocate 1 Bloom Filter mới với: P_{i+1}=r\times P_{i}
- Trong đó: 0< r\leq 1
- Phần tử mới sẽ chuyển sang insert vào tập Bloom Filter mới thay vì tập cũ trước đó.
- Khi kiểm tra thì ta check lần lượt các tập BF. Nếu phần tử được test không nằm trong bất kỳ tập Bloom Filter nào -> phần tử đó không thuộc tập S.
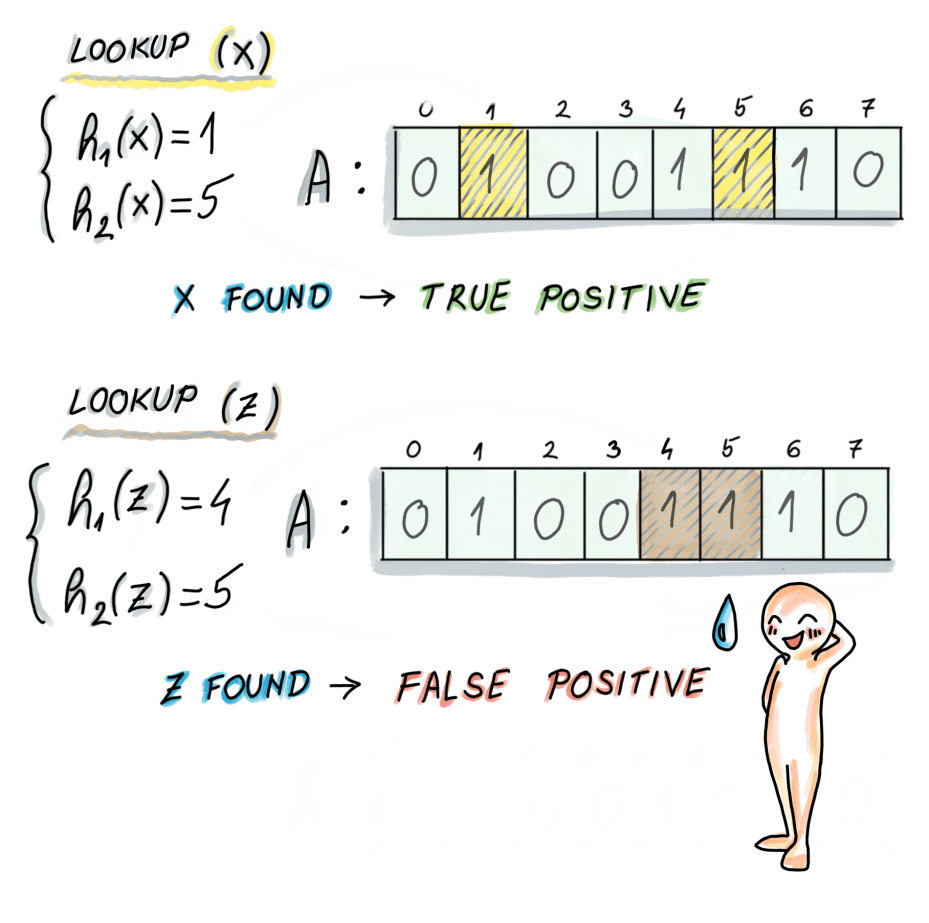
Leave a Reply